ととりにゃあ あつめて早し 最上川 それにつけても 金の欲しさよ - あるいは、ととりにゃあの語感の良さについて 【ととりにゃあ Advent Calendar 2021 Day 19】
こんばんは、そすうぽよです。 この記事はととりにゃあ Advent Calendar 2021の19日目の記事です。
概要
まずは、こちらのツイートをご覧ください*1。 https://twitter.com/totori_kpr/status/1472143266753953795
2021年12月18日現在、ととりにゃあさんの名前は「毎日進捗」となっています。 しばしば「毎日進捗ととりにゃあ」とフルネーム(?)で呼ばれることもあるようです。
毎日進捗ととりにゃあ
— olphe (@_olphe) 2021年8月15日
ツイート本文は「毎日懇親」となっています。 以下のように、Twitter上ではしばしば「<ここに四字の熟語が入る>ととりにゃあ」として親しまれています。(このパターンに収まらないツイートもありますが)
https://twitter.com/totori_kpr/status/1469494096859660288
全部最強ととりにゃあ
— ドラ@ (@u_yeiyei) 2021年12月10日
入国禁止ととりにゃあ
— 毎限遅刻 (@pu__Ne) 2021年11月30日
https://twitter.com/totori_kpr/status/1464120109190975491形而上学ととりにゃあ
— ねぼこ (@nebocco27) 2021年11月28日
六法全書ととりにゃあ
— 毎限遅刻 (@pu__Ne) 2021年11月21日
疾風怒濤ととりにゃあ
— しゃく(Suunn) (@dem08656775) 2021年11月6日
猪突猛進ととりにゃあ
— そすうぽよ (@_primenumber) 2021年9月23日
器物損壊ととりにゃあ
一汁三菜ととりにゃあ#いろいろなととりにゃあ
これらのツイートを読むと、妙に語呂が良いことに気付きます。
「ととりにゃあ」は五音なので、五・七・五のリズムの中に取り入れやすくなっています。 これまで取り上げたツイートは、そのほとんどが四字の熟語が七音や、四音+四音になっており、七・五のリズムが語呂の良さを与えているように思われます。
主題
これを拡張して、ととりにゃあを便利な五音として乱用していこうというのがこの記事の目的です。 既存研究としては、
- 「最上川」を五音として使う
もともとは漫画・アニメ「日常」らしいですが、現代ではしばしばツイッター等で観測することができます。元の句は松尾芭蕉の「五月雨をあつめて早し最上川」。
- 「それにつけても金の欲しさよ」を下の句(七・七)として使う
江戸中期に流行ったらしい。どんな優雅な上の句も破壊できるパワー下の句。
- 「メイクアメリカ グレートアゲイン」
トランプ元米大統領のスローガンが実は下の句になる。どんな優雅な上の句もトランプの顔がちらつくようになってしまう。
ということでこの記事のタイトル「ととりにゃあ あつめて早し 最上川 それにつけても 金の欲しさよ」は「ととりにゃあ」と「それにつけても金の欲しさよ」を「五月雨をあつめて早し最上川」と悪魔合体させて作った句です。
実践
ではドンドン行きましょう。
- 素晴らしい 毎日進捗 ととりにゃあ
毎日進捗、してますか?
- 使います 伝家の宝刀 ととりにゃあ
元ネタ:
電子レンジで何分温めたらいいかわからない?wフッフッフw心配することなかれwwこんな時にも役に立つのが競技プログラミング、伝家の宝刀†二分探索†を使わせていただきますぞ!wwwまずは時間を(0+2e9)/2=1e9分にセットして……\ボンッ/グオーーーー!!!!!!!!家が燃えてしまった……(悲しい)
— のいみ (@noimi_kyopro) 2020年1月28日
元ネタ:
ねこ、座布団、セガサターン、ミカヅキモ、おこづかい帳、バチカン市国、液体窒素、週刊誌、消化器系、ミソサザイ、チャイルドシート、釈迦三尊像、瞬足、Anitube、緊急脱出用出口、レレレのおじさん、大憲章、カヤック、千歯扱き、感情、陸軍の統帥権など
— しゃく(Suunn) (@dem08656775) 2019年6月10日
ドラムには、ととりにゃあさえないんだな…
ととりにゃあ 墾田永年 私財法
ウマ娘 プリティダービー ととりにゃあ
あたしンち グラグラゲーム ととりにゃあ
俺でなきゃ 見逃しちゃうね ととりにゃあ
ととりにゃあ 人には人の 乳酸菌
大型で 非常に強い ととりにゃあ
まとめ
ととりにゃあの語呂、良すぎ
*1:飯テロの意図はありませんよ、本当です
マナ回路設計と魔術アーキテクチャ 【存在しない技術 Advent Calendar 2021】
この記事は存在しない技術 Advent Calendar 2021 - Adventarの14日目の記事です。
この記事はあなたのお住まいの世界には存在しない技術をもとに記述されているため、あなたのお住いの世界ではご利用いただけません。
マナ回路前史
近代以前は、魔術を発動できるのは人間、それも多くのマナ*1を備えている人間に限定されていた。 これは、まず魔術を発動するには、一定以上のマナの密度が必要であるが、マナを蓄えられるのは人間に限られていたためである。
しかし、近代になり、マナを遮断する材料(断魔体)が発見されると、それを用いて任意の場所にマナを集めることが可能になった。 さらに、マナを集めた空間を圧縮することにより、マナの密度を魔術を発動するのに十分なだけ高められるようになると、魔術を発動できる機械である魔術機が登場した。
最初期の魔術期は発光、浮遊・移動、加熱・冷却といった単純なものに限られており、またその魔力も弱いものであった。 大きな魔力を扱うにはとても巨大な魔術機および、それに足るだけのマナが必要となるため、動力としての利用は蒸気機関の隆盛により小規模なものに限られるようになった。
一方で、微弱な魔力でよければ、小さな機構と少量のマナで魔術を発動することができ、小さな機構であれば微弱な魔力でも制御が可能である。 そこで、微弱な魔力で制御できる魔術機を複数並べ、これを連鎖的に、繰り返し発動できる魔術機が作られた。 マナを供給する限り半永久的に動き続けることから、マナ回路と呼ばれている。
マナ回路基本素子
マナ回路は、魔術を発動するのに必要なマナを圧縮する"圧縮機構"と、発動する魔術を決定する"発動機構"から構成される。
圧縮機構は、筒状の空間に集めたマナを板状の断魔体で押すことで圧縮する機構がよく用いられる。
念力はマナ回路で最もよく使われる魔術で、これによりほかの圧縮機構を制御する。

念力により単純に魔術を発動するだけでなく、圧縮機構を無効化したりすることでより複雑な制御を行える。
マナ回路例: リングオシレータ

圧縮機構を連鎖させることによって、状態を一定間隔で変化させ続けるマナ回路。 圧縮機構を制御する断魔体の位置を往復させることで、ぐるぐると魔術の発動を連鎖させることができる。
ポイントは左上橙波線で示した部分で、ここだけ他と断魔体の動かす向きを変えることで、状態がループして継続的に魔術を発動し続けることが可能となる。
現代の魔術アーキテクチャ
魔術機は、その大きさを小さくすることで必要な魔力、消費されるマナを低減することができるため、世界中の魔術師が魔術機の小型化、集積化に取り組んだ。 その結果、現代では米粒ほどの大きさに、億単位の魔術機が集積できるようになった。 それに伴い高度で複雑な魔術を大量のマナ回路素子を組み合わせて実現することが可能になった。 さらに、マナ制御技術の向上等により、強力な魔術を発動する魔術機(フォース魔術機)が実用化されるなど、ますます魔術の応用範囲は拡大している。
*1:魔力を司る粒子。目で直接見ることはできないが、空間中を飛び回っている。
『フカシギの数え方』の数え上げを、全探索のままGPGPUで高速化した 【KMCアドベントカレンダー 2021 4日目】
この記事はKMCアドベントカレンダー2021の4日目の記事です。
概要
元ネタ:『フカシギの数え方』
問題としてはN×Nマスのグリッド(頂点としては 頂点)を左上から右下まで移動する経路であって、同じところを二度通らないものの数を数える、というものになっています。
『フカシギの数え方』でお姉さんが数え上げていた問題を、実際に全探索で解いてみて、組合せ爆発の凄さを体感しつつ、GPGPUで頑張って高速化してみます。
CPUで全探索
これを全探索で解くためには、これまでに通った場所を覚えておいて、そこを通らないようにしつつ、右下の頂点までたどり着けるものを探せばよいです。 これはバックトラックによって簡単に数え上げることができます。
RustでCPU向けに実装したものがこちらになります
バックトラック部分の本体は
fn solve_impl(n: isize, visit: &mut BitVec, row: isize, col: isize) -> usize { if row == n && col == n { return 1; } let mut ans = 0; let d = [(1, 0), (0, 1), (-1, 0), (0, -1)]; for (dr, dc) in d { let new_row = row + dr; let new_col = col + dc; if min(new_row, new_col) < 0 || max(new_row, new_col) > n { continue; } let new_pos = new_row * (n + 1) + new_col; if visit.get(new_pos as usize).unwrap() { continue; } visit.set(new_pos as usize, true); ans += solve_impl(n, visit, new_row, new_col); visit.set(new_pos as usize, false); } ans }
こんな感じで容易に書くことができます。 今いる場所から4方向に対して、枠外になっていないか、既に通っていないかを確認して、大丈夫なら移動する、ということを再帰的に繰り返しています。
並列化のため、最初の2Nステップほどを並列に実行するようになっています(async-stdとfutures-rsを利用しています)。
実行するとこんな感じです(oneesan(N)でN×Nマスでの数え上げを行います)
$ cargo run --release
Finished release [optimized] target(s) in 0.54s
Running `target/release/kazoeage-oneesan`
oneesan(1) = 2, elapsed: 0.001s
oneesan(2) = 12, elapsed: 0.001s
oneesan(3) = 184, elapsed: 0.001s
oneesan(4) = 8512, elapsed: 0.002s
oneesan(5) = 1262816, elapsed: 0.019s
oneesan(6) = 575780564, elapsed: 6.891s
oneesan(7) = 789360053252, elapsed: 12195.893s
実行時間はCPUの性能等に依存します。 この調子で行くと、oneesan(8)の計算には1年半ほどかかる計算になります。
GPUで全探索
今回はoneesan(7)の計算をGPGPUで高速化してみます。 まず、GPUは並列化しないとその性能を発揮できないため、最初の一定ステップをCPUで全列挙し、そこからゴールまでの経路をそれぞれGPUで数え上げることにします。 しかし、GPUは再帰関数の処理が苦手なため、並列化しただけではとても効率が悪いです。 手元で試したところ、oneesan(6)の計算に40秒ほどかかってしまいました。
効率が悪くなる主な原因は、GPUの内部構造にあります。GPUは内部的には複数スレッドを一定数(32や64程度)束ねて、すべてのスレッドで同一の命令を実行する仕組みになっています(SIMT)。 このままだとスレッド間で計算内容が異なる場合に対応できないので、一方のスレッドの計算を行っている間は、別の命令を実行したいスレッドを待機させます。 その結果、バックトラックでの分岐が発生するたびに、一度に実行できるスレッドが絞られていき、束ねたスレッドのうち、最終的には同時に走るのは1スレッドのみになってしまいます。
今回は、再帰関数を明示的に用意した配列で実装したスタックを用いたループに展開することで、分岐して別行動になったスレッド同士が再び同時に実行できるチャンスを増やすことで、効率化を行いました。 その実装がこちらになります。
細かい点としては、ローカルメモリ消費量を抑えるために、再帰1段分のスタック用配列サイズを2bitに抑える工夫を入れてあります。
これらの工夫の結果、手元のGPUではoneesan(6)を1.8秒、oneesan(7)を1728秒で求めることができるようになりました。 oneesan(7)の計算は実に7倍高速になりました! このペースだとoneesan(8)も83日程度で求められる計算になります。ぎりぎり希望が持てる時間になりました(?) CPUとGPUの性能比を考えるとそう悪くない結果だと思います。
『フカシギの数え方』ではスーパーコンピュータは1秒間に2000億通り数えられる想定でしたが、このプログラムでは手元のGPU(GeForce RTX 3080)1枚で毎秒約4.5億通り数えられます。 現代のGPUを500枚程度用意すれば、おねえさんのスーパーコンピュータより速く数え上げることができるかもしれません。
AtCoder Heuristic Contest 003で5位(2.921T点)を取りました
AtCoder Heuristic Contestは、最近始まったAtCoderの定期コンテストで、最適解を出すのが難しい問題に対し、出来るだけ良い解を作成するコンテストです。 1週間程度の長期コンテストと、数時間程度の短期コンテストが交互に行われます。
今回のコンテストでは参加者1000人中5位と、非常にいい成績をとれました。 システムテスト前の得点(コンテスト中に表示される暫定得点、100ケースの合計)は97,323,736,361(97.32G)点、システムテスト後の得点(3000ケース合計)は2,921,245,705,250(2.921T)点でした。
今回のコンテストでやったこと、やらなかったこと、考えたこと等をまとめます。
問題概要
30*30のグリッドグラフ上で、ジャッジが指定した2点間に対して最短経路を求めるクエリが1000回投げられます。 しかし、各辺の長さは隠されており、自分のプログラムの返した経路の長さ(に0.9~1.1の範囲の一様乱数を掛けた値)のみを知ることができます。
得点は、各クエリに対して、真の最短経路aを自分のプログラムの返した経路の長さbで割った値a/bを、後半のクエリほど大きな重みを付けて和を取った値です。 1テストケースあたりの得点の上限がほぼ109点になるように定数が掛けられています。
辺の重みの決定方法が若干特殊で、というパラメータがテストケース毎にランダムで1か2になり、その値によって重みの付け方が異なります。
また、
]というパラメータもテストケースごとに一つ生成されます。(これらの値を直接知ることはできません)
 のとき
のとき
各行、各列ごとに、基準となる重みを]の範囲から一様ランダムに生成し、ここに各辺に対して
]の一様ランダムな値が加えられる。
 のとき
のとき
各行、各列ごとに、基準となる重みを]の範囲から一様ランダムに二つ(ここでは
とします)生成し、また、"切れ目"を1~28の範囲から一様ランダムに生成し、
グリッドの片方の端から"切れ目"までを
を基準、そこからもう片方の端までを
を基準とし、ここに各辺に対して
]の一様ランダムな値が加えられる。
詳細についてはhttps://atcoder.jp/contests/ahc003/tasks/ahc003_aを参照。
自分の解法
ここからは時系列順にやったことを書いていきます。見出しの得点はpretest時の得点。
愚直解 (61.67G)
Submission #22782181 - AtCoder Heuristic Contest 003
まずは入出力が正しくできるか確かめるため、常にすべての辺の重みが一定であると仮定した状態で、毎回Dijkstra法で最短経路を求めるコードを書きました。
今回は提出コードをRustで書きましたが、proconioが内部のバッファリングの影響か、インタラクティブ環境でうまく動かなかったので、温かみのある入力パースを行いました。
勾配降下法の実装 (81.59G)
Submission #22784737 - AtCoder Heuristic Contest 003
番目のクエリの応答の経路の長さ
は、辺
の重みを
、その経路に含まれる辺の番号を
とすると、
と書けます。ここで、行列を
番目の経路に辺
が含まれていれば1、そうでなければ0として定義すると、
と書くことができます。これをについて解けば辺の重みが分かりますが、辺の数が1740あるのに対し、経路の数は高々1000個しかないため、一意な解は存在しません。
また、帰ってくる経路長は乱数でスケーリングされているので、解が存在するとも限りません。
ここではとりあえず、辺の重みの近似値を、(最小二乗法)を勾配降下法によって求めることにしました。
スケーリングは正規分布ではなく一様分布であるため、最小二乗法でいいのかという問題はありますが、とりあえず計算が簡単なのと、このあとCG法を使ってみようと思ったためこうしました。
勾配降下法の高速化、辺の重みの初期値の調整 (87.74G)
Submission #22785943 - AtCoder Heuristic Contest 003
雑に疎行列演算等を実装したところ、各クエリに対して20回しか勾配降下法のステップを回しただけで1200msほどかかっていたので、不要なメモリ確保をなくすなどの高速化をして、30ステップほど回すようにしました。 また、未探索の辺を積極的に調べるため、未探索の辺の重みを期待値である5000よりも若干小さくしました。
高速化、学習率の調整 (92.19G)
同時に疎行列ベクトル積を高速化して、クエリごとに50ステップ程回せるようになりました。
get_unchecked (配列の境界チェックをせずに配列の要素にアクセスするunsafe関数)使ったら速くなった!(これでいいのか?)
もう少し1ステップで更新する大きさ(学習率)増やしても行けそうだったので、5倍(0.0001→0.0005)にしました。 また、Dijkstra法は負辺/負閉路があるとまずいので、辺の重みを1000-9000の間になるようにclampした(Rust 1.42.0にはclampがなかったのでminとmaxで書いた)。
共役勾配法の導入 (92.83G)
二乗誤差の最小化は、実は方程式
(正規方程式)を解くことによっても求められます。
これは線型の連立方程式なので様々な方法で解けますが、行列サイズが1740*1740とかになるのでガウスの消去法等では計算量が大きすぎます。
しかし、
はほとんどの要素が0の疎行列なので、これを生かした高速な求解アルゴリズムがいくつか存在します。
ここでは共役勾配法(CG法)を使いました。
大きすぎる/小さすぎるweightの抑制(正規化) (93.15G)
辺の重みは1000-9000の間にありますが、経路長に誤差が乗っているため、方程式はその範囲外の値を解としてもってしまうことがあります。
これを補正するために、も最小化対象になるように、行列
に入れました。
さらに辺の重みの初期値をいじって93G点に乗せました。
重大な事実に気付く
ここまで初日の内容で、このときは1桁順位で満足していましたが、土日が明けた頃には40位程度まで落ちていました。
で、上位の得点を見ると、すでに96G点台になっていました。
この時点ではなんとまだパラメータの存在に気付いておらず、1740辺に対し1000経路では明らかに情報が不足して、こんなに精度が出るのはおかしくないか?と思っていました。
何か勘違いとしているとまずい、ということで問題文やテストケースの生成方法をよく読むことにしました。
すると、というパラメータがあり、とくに
の時は同じ行/同じ列の辺の重みはほとんど同じになっていることに(今さら)気付きました。
たしかにこれを使えば大きくスコアを改善できそうです。
隣り合う辺の重みの差の抑制 (95.53G)
ということで、同じ行/列の辺であって、隣り合っているものについて、その重みの差を最小化対象に入れました。
これはに片方の辺に
、もう片方の辺に
を掛けて足す行を追加すればよいです。
解と行列の使いまわし (96.85G)
いくらCG法が高速に収束するとはいえ、TLEしない10回程度の反復では、得られる解(辺の重み)の精度は限られています。 そこで、辺の重みベクトルをクエリ間で使いまわすようにします。すると、前回得られた解からスタートするので、多くの場合今回求めるべき解の近くからスタートすることになり、収束が速くなります。 また、これまでは行列やベクトルをクエリごとに再構築していたのを、使いまわすようにして高速化し、反復回数を増やせるようにしました。
この時点で暫定2位まで来ました。びっくりです。 さすがに3日目まで問題文をよく読んでない人ばかりではないと思うので、おそらくCG法によって1740辺個別に重みを推定できるようになったのが大きく効いたのではないかと思います。
重みスケーリング (97.02G)
のときは、行中のどこかで辺の重みが一気に変わる場所が存在するはずで、このとき隣り合う辺の重みの差を抑制していると、真の重みから遠い重みを推定してしまいます。
そこで、隣り合う辺の重みの差によるペナルティーがどれくらいかかっているかに応じて、ペナルティーを軽減したり増やしたりするようにしました。
パスの長さによる正規化 (97.13G)
これまで、各経路に対して、 (と他の正規化項)の二乗和を最小化してきましたが、
は経路中の辺の数が多いほど大きくなりやすいです。
二乗和の最小化なので、この場合長い経路ほど頑張って誤差を最小化しようとすることになります。
しかし、得られる経路の長さが真の値に対して0.9~1.1倍スケールされていることを考えると、短い経路の結果も長い経路の結果も同程度に重視すべきです。
そこで、経路中の辺の数を用いて、
(と他の正規化項)と正規化してやると、スコアが伸びました。
 の推定、その他微調整 (97.32G)
の推定、その他微調整 (97.32G)
かどうかをlossを見てアドホックに推定して、それに応じてペナルティーをいじるようにしました。
あとは細かい改良を積み重ねたり、optunaでハイパーパラメータチューニングをしたりして、スコアを積み上げていきました。
最後までM=2でDが小さいときに対するうまい対処法を思いつけなかったのが残念です。
解法そのものとは関係なくやったこと
複数テストケースを並列で走らせて、たくさんのテストケースについての得点を素早く集計する
問題の性質上、テストケースによって点数が大きくずれる、また、パラメータによって得点傾向が違うことから、少数のテストケースのみで変更点の有効性を確認するのは危険です。 コンテスト中の提出は30分に一回しかできず、また、100ケースしかないため、かなり大きな改善でないと有効性を言えるほどの点差がつきません。 さらに、改善が進むにつれ、一つの変更による得点の上昇が少なくなっていくので、その分テストケースの数を増やしていかないとテストケースに対して過学習を起こしやすくなります。
そのため、ローカルでたくさんのケースについて得点を集計する仕組みを構築しました。 複数ノードにバイナリをばらまいて、各ノードで計算を走らせ、それを集計するスクリプトをRubyで書いて、コマンド一つでできるようにしました。 最終的には家の計算機5台(Ryzen 7 Pro 4750GE * 4 + Ryzen 9 5950X * 1)の計48コア96スレッドで7680ケースについて回すようにしました。
性質上、並列度はテストケースの数だけ増やせるはずなので、次回の長期コンテストまでにはAWS Lambda等を用いて1000並列とかで回せるベンチマークシステムを構築したいです。
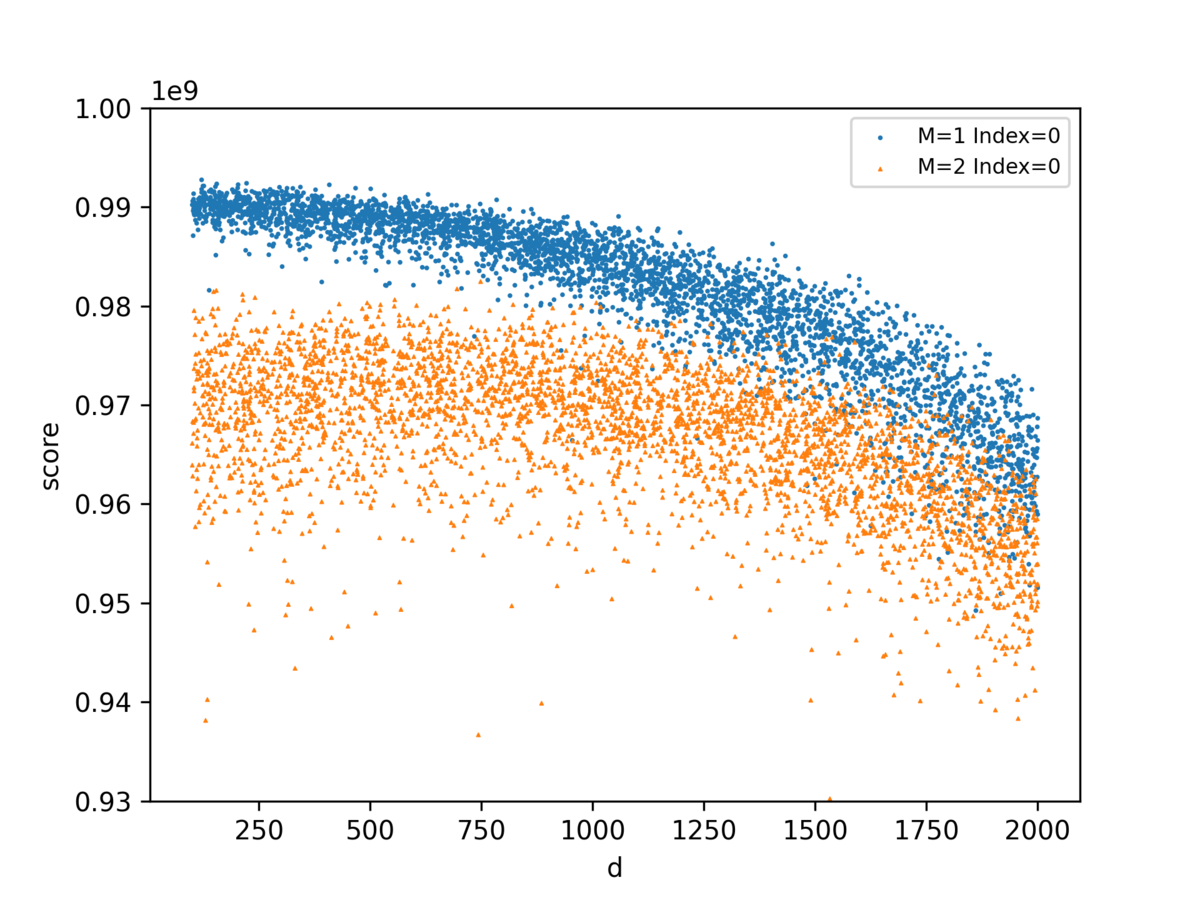
M,Dの値とスコアの関係をプロット
これも考察に大いに役立ちました。のときだけでなく、
の大きいときもかなりスコアが下がっていることが確認できました。
コードをいじった時にも、どういうところでスコアが改善・悪化しているかが見てわかるので良かったです。
optunaによるハイパーパラメータチューニング
使いどころが難しい(本質的な改善の方が大事)ですが、次のような場合に使ってとてもいい感じでした。
- 他のパラメータとの相対的な重みの大きさが変わるような変更の後
パスの長さによる正規化を実装したとき、経路に関するlossは(辺の数で割られるので)かなり小さくなります。 それに応じて他の正規化パラメータの大きさも小さくする必要がありますが、複数パラメータ間のバランスをとるのは大変で、ここでoptunaで自動的にチューニングできたのはとても便利でした。
- これから寝るとき
寝てるだけでスコアが良くなって便利。
- もうできることが思い浮かばないとき
ボーっとしてるだけでスコアが良くなって便利。
- 計算機を温めたいとき
マイニングでもしとけ。
512ケース程度ではかなり過学習してしまうので、かなり計算資源が必要なのが難しいところだと思います。 最初に128ケースまわしてとても悪そうだったらそこでやめて、悪くなさそうならもっとたくさんのケースを回す、とか工夫の余地はありそうです。
特に、今後クラウドで回そうとするならば、そのへんの計算量削減策を考えないとすぐにお金が融けていきそうです。
やったけどうまくいかなかったこと
隣接辺の重みの差をペナルティにするのではなく、ダミー辺との重みの差をペナルティにする
- M=2のときに全然上手く行かなかった
- M=1のときもスコアの分散が大きくなっただけであまり改善されず
- 辺ごとの重み推定を捨てて、行ごと(60変数や120変数/180変数のモデルにする)でやればよかったかも
経路の結果を正規化する際に、辺の数ではなくスコアで正規化
- 他のパラメータの重みもずらす必要があるのでoptunaで最適化もしたが、それでもだいぶ悪かった
- 経路長に乱数がかかった後の値がやってくるのがまずそう?
やっておけばよかったこと
 の推定値によるモデルの切り替え
の推定値によるモデルの切り替え
これをできなかったのは結構良くなかったな、という気持ち… M=2の時のモデルをどうするか、というのが本質的に難しそうですが… Dが大きいときには、わりとできることは少なそうで、ここの改善はあまり期待できなさそうです。
事前の環境整備
インフラ回り等、事前に準備できることは結構あるはずなので、そのへんを次回の長期コンまでにやっていきたいです。
感想
とてもよくできた問題だと感じました。 これがM=3とかがあると、割と打つ手がなさそう(複雑度に比べて、得られる情報が少なすぎるため)で、かといってM=1だけだとすぐほぼ理論値までたどり着いてしまうはずで、この辺の塩梅が良かったように感じます。
結果にはとても満足していて、望外のいい結果を得られてとてもうれしいです。 今後もいい結果を残せるように頑張ります。
AtCoder Heuristic Contest 001 解法メモ
最終スコア(システムテスト後)は980,823,067,375点で95位でした。
自明解の生成
広告の希望(x, y, r)に対して、長方形( (x, y), (x+1, y+1) )は解の条件を満たす
スコア計算
- 解の条件を満たしているかを判定する
- 満たしていれば、各広告についての点数の和を取って全体のスコアを算出する
基本方針
山登り法、乱数の値の幅を徐々に小さくする
1点探索 (resize_1way)
広告を一つランダムに選択する 任意の方向に適当な大きさ伸ばし/縮めることを試す これを何度も繰り替えす
1点探索 (move)
他の広告の邪魔になっているところを解消するため、広告を平行移動する 広告を一つランダムに選択する 任意の方向に適当な距離移動させることを試す
2点探索 (redelineate)
接触している2つの広告のペアをランダムに選択する 接触している境界線をどちらかの方向に適当な距離移動させることを試す
スコア計算の最適化
- 解の条件を満たしているかを判定するのがO(n2)かかっており、遅い
- 操作前に解の条件を満たしていることを仮定すると、上記の操作では、変更した広告と他の広告のペアについて、解の条件を満たしているかを判定すれば十分
- 判定にO(n)、スコア計算にO(n)で全体でもO(n)でスコアを計算できる
- また、スコア計算自体も差分更新できる(依然として判定にはO(n)かかるので、オーダーレベルでの改善にはならない)
- そもそも、スコアをずっと持っておく必要もなく、スコアが増大するかどうかが関心の対象なので、変更した広告の得点だけを見ればよい
greedy
何度も改善を繰り返し、制限時間を迎えたとき、shake操作等により広告間に隙間ができていることがある もったいないので、改善できるなら貪欲に改善する
redelineate skip 最適化
自明解から広告を拡大している途中では、広告同士が接触していることはまれ 2点探索は接触判定にO(n2)かかっており遅いため、最初のうちは行わないことで高速化
全体再配置 (gravity)
方向をランダムに選択する すべての広告を、他の広告にぶつからず、位置の制約を満たす範囲で選択した方向に平行移動する この際、平行移動の代わりに拡大してスコアを改善できれば、する
1点探索 (resize_2way)
1方向だけに対してサイズ変更をした場合、すでに要求の大きさに近い面積になっていると、これ以上拡大・縮小が不可能になることがある 2方向に対してサイズ変更をすることで、これを緩和する
複数回探索 (多点スタート)
局所解に嵌ってしまうと、抜け出すのは困難なため、何度も探索してもっともよさそうな解に対してさらに最適化を掛ける
2点探索高速化
2点探索では、接触判定の計算量O(n2)が支配的で、その後の試す部分では解の条件判定にO(n)掛かる他は定数時間で終わる。 そのため、一度接触判定をしたら、その後たくさんのペアに対して変更を試すことで、変更当たりの計算量を削減して高速化できる。
2点探索 (dodge)
接触面を平行移動するのではなく、接触面を0にするようにそれぞれの広告の大きさを変更した後、もとよりスコアが改善するように接触面のあった方向に広告を伸長する
resize_1way強化
resizeの結果他の広告にぶつかった場合も、そこで失敗判定にせずに、ぶつかった広告を縮小して回避できるときは回避することを試す
AtCoder橙/Codeforces International Grandmasterになりました
この記事は色変記事アドベントカレンダー1日目の記事ではありません。
AtCoderで橙色、CodeforcesでInternational Grandmaster(IGM)になったので振り返り記事を書きます。
感想
Codeforces IGMは昔からの憧れでもあったので、とても感慨深いものがあります。というか、自分がなれるものだとは思っていなかった節があります。 一方で、AtCoder橙は訓練を積めばそのうちなれると信じていたんですが、結果としてCodeforces IGMの方が早く達成できてしまいました。こういう人あんまりいないみたいで謎です。
やったこと
ABC-EF埋め
2020年2月ごろに全部埋めた。(今は数問埋まっていない…) 典型問題の処理がうまくなると、難しい問題の方針も立てやすいし、なにより序盤の簡単な・典型的な問題で時間ロスをしにくくなると思います。
黄Diff(🧪含む)埋め
2020年4~5月 AtCoder ProblemsでDifficultyが黄色になっている問題を全部解きました。黄色Diffばっかりやるのは黄Diff問題に頭が過学習する感じがあってあんまりよくなくて、橙や青Diffも混ぜて解くべきでした。 文字列系の問題は、これまでZ-algorithmとかSuffix Arrayとかほとんど使ったことがなかった(解けない or ローリングハッシュで殴りがち)ので、ここで復習できたのは良かったです。
同じ黄Diffでも体感難易度にはかなりばらつきがあって、これは自分の得意不得意の偏りだけでなく、そもそものDifficultyの算出精度の限界もありそうです。
黄Diffを全部埋めた後は橙Diffと青Diffを解こうとしましたが、橙Diffは全然解けなくて挫折してしまiいました。今年は橙Diffと正面から向き合っていきたいです。
コンテストに出る
これが自分にとってはかなり効いた感じがします。 というかこれまであんまり出てなかったのが良くなかったです。
コンテスト時間いっぱいあきらめずに噛り付くとか、実装の簡単な方針を考えるとか、複数の問題が残っているときにスッと戦略を切り替えるとか、そういう力が結構養われたように感じています。
今後について
この先の色変目標となると、AtCoder赤とかCodeforces Legendary Grandmasterになりますが、正直全然なれる気がしないので、あまり気負わずじわじわと強くなれるといいなと思っています。
どうしても平日は労働で疲弊してしまうのと、趣味で競プロ以外にもやりたいことがいっぱいあって、正直あまり多くの時間を割けない気はしますが…
まずはAtCoder橙/Codeforces IGMで安定できるようにしていきたいと思います。
あといい加減今使っている競プロライブラリがつらい(C++03/11、ICPC想定で可読性より短さ重視)ので、一新していくつもりですが、今のところリポジトリだけ作って放置しています…
フラグメントシェーダを用いて、VRChatのワールドで計算機を作る 【KMCアドベントカレンダー 2日目】
この記事はKMCアドベントカレンダー 2日目の記事です
概要
最近遊んでいるVRChatというゲームにはユーザーの作成したアバターやワールドをアップロードできる機能があります。さらに、アバターやワールドのバーテックスシェーダー*1/フラグメントシェーダー*2を自分で作ったものに差し替えてアップロードすることができます。
これを悪用(?)し、fragment shaderにBrainf*ckという難解プログラミング言語のインタプリタを実装することで、VRChatで、ゲームプレイ中に指定した任意の計算を実行することができるような仕組みを実装しました*3。
VRChatのワールドでBrainf'ckインタプリタ動いた! pic.twitter.com/92pfXoijzk
— そすうぽよ (@_primenumber) 2020年11月30日
#VRChat のBrainf*ckインタプリタワールドを更新した
— そすうぽよ (@_primenumber) 2020年12月1日
- ソースコードをもっと複雑なものに置き換え(ハノイの塔を解くプログラム)
- 標準出力を文字として表示、改行にも対応
- ついでにソースコードの表示もフォントを使うように
[フォント周りの技術協力: @sv1rc ] pic.twitter.com/jj5YIOlL46
GPGPUとは
みなさんが普段ゲームなどのグラフィック処理をするときには、大抵GPU(Graphic Processing Unit)という装置*4が使われます。 GPUは、三次元のポリゴンの移動・変形や、陰影処理等の計算を行うために、たくさんの演算機を備えています。
この演算機の演算能力をグラフィック処理以外にも使おうというアイデアが、GPGPU(General Purpose compution on GPU)と呼ばれています。 今日では、GPGPUはCUDAやOpenCL、OpenACC、グラフィックAPIのCompute Shader等によって比較的手軽に行えるようになりました。
VRChatにおける演算
VRChatはゲームなので、これらの便利なGPGPUプログラミング環境を使う方法はありませんが、アバターやワールドのバーテックスシェーダー/フラグメントシェーダーなどである程度の計算を行うことができます。 バーテックスシェーダーでは各頂点ごとに、フラグメントシェーダーでは画面の各画素ごとにシェーダーのプログラムが実行されます。 が、通常これらのシェーダーは状態を保存したり、他の頂点/画素と通信することはできません。GPUはたくさんのプログラムを並列で計算することでスループットを稼いでいるため、単一の要素に対する計算はあまり高速ではありません。 したがって、まともな速度でゲームが進行するためには、1頂点/画素あたりの計算量は十分小さくないといけません。 つまり、これらのシェーダーで大規模な計算をすることはできません(完)。
という問題を解決する方法がいくつかあり、今回はCustomRenderTextureを使いました。
CustomRenderTextureでは、ダブルバッファリングを有効にすることで、フラグメントシェーダー上で「前のフレームの演算結果」をテクスチャの色情報として得ることができます。また、他のテクスチャ(他のCustomRenderTextureを含む)を入力として受け取ることもできます。
これを利用すると、テクスチャ上に状態を保存することで、フレームをまたいだ計算が可能になります。
また、前のフレームの別の画素の色情報を得ることもできるので、フレームをまたぐことで別の画素と通信が可能になり、並列計算への道が開かれます。
テクスチャは2048x2048程度は問題なく持つことができるため、400万ワードほどのメモリを持つことができます。
これにより、理論上は任意の計算を他のプレイヤーのGPU上で走らせることができます。 とはいえ、shaderのプログラムはアップロード時に決定されてしまうため、このままでは動的に(ゲームプレイ中に)実行するプログラムを差し替えることはできません*5。
そこで、fragment shaderに何らかの仮想計算機を実装し、何らかの方法でゲームプレイ中にプログラムを与えることで、ゲームプレイ中にプログラムを差し替えて計算することができるようになります。
Brainf*ck
Brainf*ck*6は難解プログラミング言語と呼ばれる、「プログラミングすることが難しい」プログラミング言語のひとつです。Brainf*ckではソースコードは8つの命令のみで構成されていて、それぞれごく単純なことしかできません。 詳しくは、Brainfuck - Wikipediaなどを参照してください。 例えば、現在VRChatのBF Interpreterワールドに置かれている、4段のハノイの塔のパズルの解法を計算するプログラムは次のようになります。見やすさのために改行やインデントを入れています。 gist.github.com
Brainf*ckでまともな計算をすることはとても難しいですが、Brainf*ckの処理系(コンパイラ/インタプリタ)を作ることは(他のプログラミング言語に比べて)比較的簡単です。 今回は今後より実用的な処理系を作る練習として、実装の容易なBrainf*ckインタプリタを実装することにしました。
処理系の構成
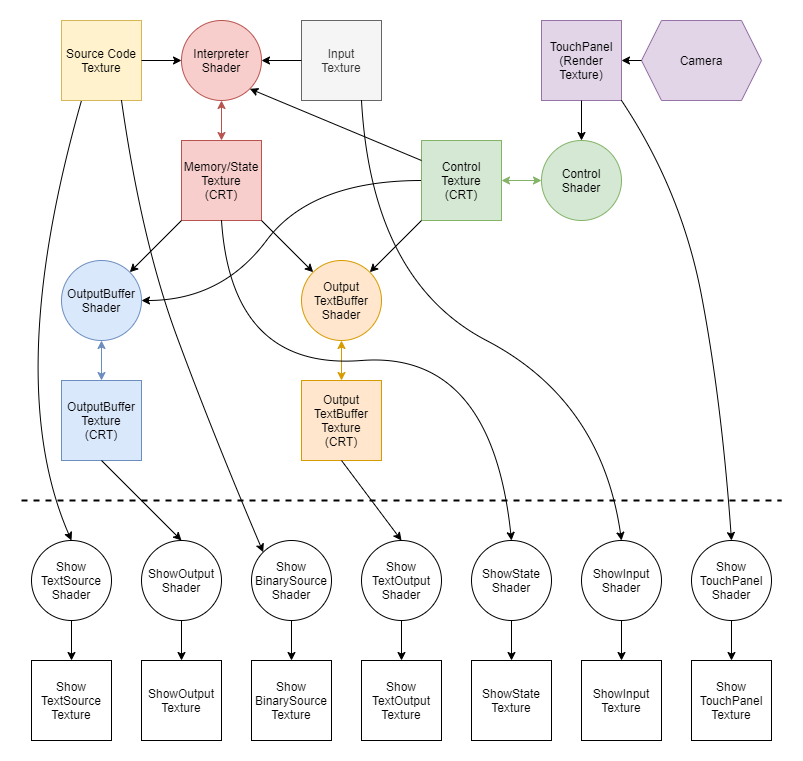
処理系本体
処理系の本体はこの図の赤色の部分で、Interpreter Shaderが計算を、Memory/State Textureが状態を保存する役割を果たしています。
Memory/State Textureは64x64pxのRGB値を持ち、最初の1行が命令カウンタなどの状態管理用レジスタ、残りの行がBrainf*ckプログラムの使用するメモリ領域になっています。
状態管理レジスタは[命令カウンタ, データポインタ, 動作モード(実行/前方にジャンプ/後方にジャンプ/プログラム終了), 入力済みバイト数, 出力済みバイト数, 出力データ, ジャンプ時の[ ]の対応を見るカウンタ, 出力validフラグ]の8個となっています。
シェーダー内部では、R,G,Bの各色に対して8bitのデータをエンコードして持たせることで、1画素あたり24bitのデータを保持しています。
処理系の動作はおおむね次のように動きます。
状態管理レジスタに該当する画素: 各レジスタの次フレームの値を計算する
- 命令カウンタなら、1進めたり、ジャンプ命令では戻ったり
- データポインタは> <命令を実行する状態になっているときのみ増減させる
- 出力validフラグは、.命令を実行する状態になっているときのみ1、それ以外を0にする
など
メモリ領域に該当する画素: データポインタが自身のアドレスと一致しているときのみ、いま命令カウンタが指している命令が+ - ,なら、適切に値を変更する
このような実装により、1フレームに1命令(ジャンプ時はジャンプ場所を線形探索するため何フレームもかかりますが)処理する処理系ができました。
Control Panel
ワールドに設置したカメラでアバターを検出することにより、タッチパネルを実現し、状態のリセットを行うことができます。カメラで撮影した画像をRenderTextureに出力する機能を利用しています。これにより他のシェーダーがプレイヤーの操作を受け取ることができます。 Control Shaderはカメラの入力画像をparallel reductionにより使いやすい形に変換しています。
Output Buffer / Output Text Buffer
出力バッファー用のシェーダーとテクスチャです。 Memory/State Textureの出力validフラグが来たら1文字読み、次の書き込み位置を一つずらします。 Output Text Bufferでは、改行が来たときにも次の書き込み位置を次の行の先頭に移動します。
表示用のシェーダー/テクスチャ
処理系内部では数値はRGB値にエンコードされているので、これを人間が理解できる形式に変換する処理が必要です。 デバッグ用の出力は2進数に変換して黒/白で表示しているだけです。 ソースコードと出力のテキスト表示は、しみさんの
- テクスチャにテキストとフォントを焼いてるので、たくさんの文字が入ります
— 西米 (@sv1rc) 2020年11月21日
- UI に依存しないので、アバターにも「読める本」を仕込めます pic.twitter.com/tfT6P2L4Jw
をお借りして実現しています。図がぐちゃぐちゃになるので、上の構成図からはフォント用のテクスチャは省略してあります。 フォントデータが2値画像(をRGBA32bitに詰め込んだもの)なので、大きく表示したときにジャギーが目立つと感じたので、中央値を基にしたジャギー軽減アルゴリズムを実装しています。
#VRChat Brainf*ckインタプリタワールド
— そすうぽよ (@_primenumber) 2020年12月2日
- フォントを変更して[]がうまく表示されるようになりました [thanks: @sv1rc ]
- フォントのレンダリングに簡易なジャギー軽減アルゴリズムを導入した(斜め45度の線がだいぶ良くなって、"2"とかを見るとわかる)
- 改行されたときに↵を薄く表示 pic.twitter.com/VtJNN1WIFc
今後の課題
- ソースコードを編集する機能がないので、簡易なテキストエディタを実装して、プレイ中にソースコードを差し替える仕組みを作る
- ワールドにはインターネット上から画像をダウンロードする方法が存在するので、これにより外部から動的にソースコードを持ってこれるようにする
- より高級な計算用仮想マシンを実装する
- Piet DM's Esoteric Programming Languages - Piet の処理系ができると見た目に楽しそう ただし、カラーブロックの連結成分の大きさを高速に求めるのは簡単ではない。
- 並列計算が可能な仮想マシンとアーキテクチャを実装する
- フラグメントシェーダーはその仕様上、「指定した場所に値を書き込む」という仕組みの実現が難しい(複数フレームを掛けてデータをルーティングする必要がある)
- 高級で並列計算可能な計算機で、実用的な計算速度を得る