将棋の局面の256bit完全ハッシュを10倍速くする
将棋の局面(手番+盤面+手駒)をハッシュ化する方法はいくつかあり、Zobrist Hashやハフマン符号を用いた完全ハッシュが知られています。
ハフマン符号を用いると256bitの完全ハッシュを作ることができます。やねうら王ではPackedSfenという名前で実装されているので、以後PackedSfenと呼びます*1。
PackedSfenでは、玉以外の7種の駒を次のように符号化することで256bitに収めることに成功してます。
| Piece Type | bit1 | bit2 | bit3 | bit4 | bit5 |
|---|---|---|---|---|---|
| Pawn | 0 | - | - | - | - |
| Lance | 1 | 0 | 0 | - | - |
| Knight | 1 | 0 | 1 | - | - |
| Silver | 1 | 1 | 0 | - | - |
| Gold | 1 | 1 | 1 | 0 | - |
| Bishop | 1 | 1 | 1 | 1 | 0 |
| Rook | 1 | 1 | 1 | 1 | 1 |
この方法は、盤面を空き升を含めて順に符号化するためかなり遅く、ハッシュテーブル用のハッシュ関数には、差分更新の軽いZobrist Hashを用いることがほとんどです。
今回、256bitに収まる完全ハッシュを比較的高速に求める方法(SSPFv1*2と呼ぶことにしました)を実装したので紹介します。
SSPFv1の仕組み
実は、今回の手法もハフマン符号を用いています。そればかりか、駒種を符号化する規則もPackedSfenと同一です。異なるのは、それを計算してビット列として詰める方法です。
PackedSfenでは盤面を1升目の1ビット目、1升目の2ビット目、…、2升目の1ビット目、…、81升目の最後のビット、の順で格納します。
これをSSPFv1では1升目の1ビット目、2升目の1ビット目、…、81升目の1ビット目、1升目の2ビット目、…、81升目の2ビット目、1升目の3ビット目、…の順で格納します。
ハフマン符号では駒ごとに必要となるビット数が異なりますが、必要ないビットは格納せずに飛ばします。 1ビットごとに飛ばす・飛ばさないを見て格納すると余計に遅くなりそうですが、ここで近年のx86_64CPUに実装されているPEXT(Parallel Bit EXTract)という命令を使うことができます。
PEXT命令はdata, maskの2オペランドを取り、dataのうちmaskで1が立っている桁のビットを下位に詰めたビット列を得ることができます。
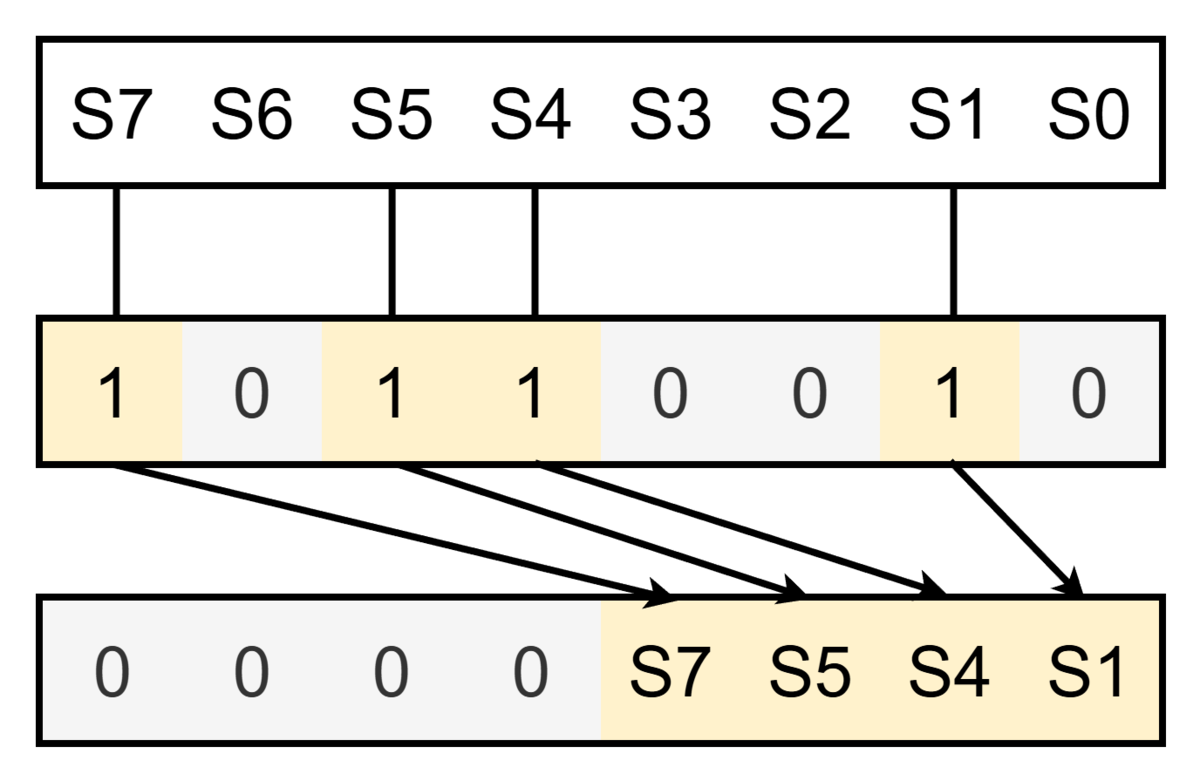
ハフマン符号の2ビット目を得たい場合、2ビット目が必要な香桂銀金角飛のorをとったビットボードをmaskとし、銀金角飛のorを取ったビットボードをdataとして、81bitのpextを行うことができればよいです。
PEXT命令は32bit, 64bitの入力にのみ対応していますが、64bit*2のビットボードに対するpext操作もpopcount命令を併用すれば数命令で求まります*3。
同様にして、ビットボードの操作とpextですべての駒に対応するビット列を順次求めることができるため、非常に高速に完全ハッシュを求められるという仕組みです。
実装はリポジトリのsrc/sspfv1.rsにあります。
ベンチマーク
速いというからにはベンチマークを取らねばなりません。必ず。 今回PackedSfenとSSPFv1をそれぞれ実装し、速度を比較しました。チューニングの結果、PackedSfenの実装もやねうら王のものより高速になっています。
- CPU: Ryzen 9 7950X3D
- OS: WSL2 on Windows11
- Compiler: rustc 1.94.0-nightly (fe98ddcfc 2026-01-17)
| flags | PackedSfen (ns/iter) | SSPFv1 (ns/iter) | Speedup |
|---|---|---|---|
| target-cpu=native | 106.36 | 10.23 | 10.3x |
10倍以上速く、指し手生成等と比べても十分高速です。
行動デッキ
最近、というか今年一年は「本当はできるのに、なぜか一度もやっていないこと」を探して、実践してみることを心がけるようにしてきた。
その多くはしょうもないことで、例えば刺身を柵で買って自分で切る、普段履きにスニーカー以外を買ってみる、とか。
実行可能だがやったことがないことを自分で発見するのは意外と難しい。
私は、自分の可能な行動の集合を「行動デッキ」と呼んでいる。その部分集合として今可能な行動の集合「手札」があり、その中から一つ以上を選んで行動する。
経験のない行動を行動デッキに入れるのは、なにか外的な要因がなければ、自分で探して回らなければならない。どうやら、このことに最近になって自覚的になった。
自分で生活を営むようになり早n年*1、このくらい経つと「これまでにやったことのある行動」だけで生活が完結するようになってしまう。
ちゃんと生活できているということでそれはめでたいのだが、如何せん刺激に乏しい*2。
それに堪えかねて、脳が新鮮な刺激を求めているのかもしれない。
新しい行動カードを発見してやってみると、なんだか少し成長した気分になる。 でも、それは単にいつでもできるそのことを、最初にやったのが今であったというだけだ。
周りから見たら普段と変わらない私が見えていたことだろう*3。
それでも、行動デッキを拡張するのは楽しいので続けていきたい。
来年はもっといろいろなことに手を出したいなあ。
現地に行けるタイプの無限遠点
平面上では平行線は交わらない。 だが、「無限遠点」と呼ばれる点を追加することで平行線を交わるようにすることができる。
無限遠点の構成
無限遠点の加え方はいろいろあるが、ただ一つの(平面上にない)点Pを無限遠点として追加する方法を考える。
平面上の円を考える。 円周上の1点を固定して、円の半径をだんだん大きくしていくと、部分的には直線にかなり近くなる。
さらに大きくして半径を無限大にすると…直線になった!直線は半径が無限大の円だと思うことにしよう。 このとき、すべての直線は点Pを通る。
二つの円があるとき、それらは交点を持たないか、1点で接するか、2点で交わる。 これは直線を半径無限大の円として扱う場合にも拡張できる。
二つの直線は、平行線でなければ、平面上の1点と無限遠点の2点で交わる。 平行線なら、無限遠点で「接する」ということにする。 (半径が有限の)円と直線も、交点を持たないか、1点で接するか、2点で交わる。
このようにしてめでたく平行線を交わらせる(接させる)ことができた。
本当はもう少しちゃんとした正当化をするべきだが、この記事はそれが本題でないのでよいこととする(興味のある人は「反転幾何学」などで調べてみてほしい)。
無限遠点に行く
無限遠点を考えることで、平行線が交わるようにできることが分かったが、逆に平行線が交わるような点は、すべて無限遠点である(平面内では交わらないため)。 つまり、平行線が交わっている場所に行けば、無限遠点に行ったことになる。
さて、京都の街は碁盤の目のように通りが敷かれており、東西方向の通りと南北方向の通りで市街地が構成されている。東西の通り同士、南北の通り同士は当然平行に走っている。
京都の比較的名のある通りである三条通と御池通は、ともに東西方向に平行に走っている――が、なんとこの二つの通りが交わる「三条御池」交差点が存在する!これはどう見ても無限遠点だろう。
無限遠点へのアクセス
通常、無限遠点は無限に遠いためアクセスが困難だが、三条御池交差点は鉄道の力により簡単に行くことができる。
JR京都駅から
京都市営地下鉄烏丸線「烏丸御池」駅で京都市営地下鉄東西線に乗り換え、「太秦天神川」駅下車すぐ
阪急京都線から
阪急「大宮」駅または「西院」駅で嵐電に乗り換え、「嵐電天神川」駅下車すぐ
無限遠点に行く際の注意
通りを歩いていく場合、無限に時間がかかる危険があるため、注意すること(地下鉄がおすすめ)。
効率的かつハードウェアフレンドリーな3値データのエンコーディングの提案 【Densely Packed Ternary, DPT】
皆さん、3値データ、使っていますか?
どうやら最近はLLMの文脈で3値データが注目を浴びているようです。
この論文では、重みに3値データを使うことで大幅な軽量化が可能、という触れ込みです。 ここ一か月でも動作する実装が公開されたり、続きの論文が発表されるなど、ホットな状況が続いています。
3値(ternary)データとは、3種類の値を取るデータのことです。
3種類の値の例としては、の他に、
や
、
、
などもあります。
✊↔0, ✌↔1, ✋↔2のように、あらかじめとの対応関係を決めておくことで、これらの値を
で表現することができます。
以下、3値データは
の形で表されているものとします。
用語・記法
2値(binary)データの大きさはbit(s)で表しますが、3値データの大きさを表すのにはtrit(s)が用いられます。 tritという名前はtrinary digitから来ているそうです。
2進法・3進法・16進法表記の接頭辞としてそれぞれ0b, 0t, 0xを使います。(10進法表記で)89は16進法表記で0x59、2進法表記で0b1011001、3進法表記で0t10022となります。
10進法表記と同じく、上位桁が前(左)に来るように並べます。
既存のternay->binaryエンコードアルゴリズムの課題
3値データをバイナリデータにエンコードすることを考えます。 5tritのデータは243通りあるので、8bit(256通り)のバイナリにエンコードすることができます。 5tritより長いデータは5trit単位で区切り、それぞれを8bitにエンコードしてから連結すればよいです*1。 こうすることでそこそこの空間効率を実現しつつ、計算コストを抑えることができます。
5tritを8bitにエンコードする方法として、愚直に3進2進変換をするアルゴリズムを考えます。
このアルゴリズムでは、デコード時に繰り返し3で除算する必要があり、デコードの計算が比較的重いという問題があります。
あらかじめ倍しておいて、デコード時には3を繰り返し掛ける、という方法もあります。
詳細は解説記事(英語)を読んでください。
3を掛けるのはx + (x << 1)でできるため、デコード時には乗算器は不要で、加算器だけあればよいです。
しかし、今度はエンコード時に定数による除算(乗算に置き換え可能)が必要になってしまいます。
このエンコード処理を論理回路として実装すると、回路規模がかなり大きくなってしまいます。
Densely Packet Ternary(DPT)エンコード
今回紹介するDensely Packed Ternary(DPT)はエンコードもデコードも比較的低コストでできるアルゴリズムとなっています。
DPTでは同じく5tritを8bitに変換します。 まず、5tritを2,2,1tritの「サブブロック」に分割し、以後各サブブロックをB1, B2, B3とします。B1が下位trit側でB3が上位trit側となることに注意してください。 各サブブロックを3進2進変換でそれぞれ4,4,2bitsに変換します。 2tritを4bitに変換する際、上位tritに3を掛けるのに乗算が必要ですが、定数3と0,1,2のいずれかを掛けるだけなので、0,3,6から選択する回路で実現できます。
大きい数、小さい数
DPTにおいて重要な概念である、「大きい数」「小さい数」について説明します。
2tritを3進2進変換でエンコードすると、
| ternary | binary |
|---|---|
| 00 | 0000 |
| 01 | 0001 |
| 02 | 0010 |
| 10 | 0011 |
| 11 | 0100 |
| 12 | 0101 |
| 20 | 0110 |
| 21 | 0111 |
| 22 | 1000 |
となります。ここで、binaryの最上位ビットに注目すると、1通りだけ1でそれ以外は0です。 デコードするときには、
- 最上位ビットが1なら、下位ビットを見ずに22であると確定。
- 最上位ビットが0なら、下位3ビットの組み合わせ全8通りにそれぞれ対応する値(00~21)があるのでそれを求める。
1tritをエンコードするときは、
| ternary | binary |
|---|---|
| 0 | 00 |
| 1 | 01 |
| 2 | 10 |
となり、デコード時にはbinaryの最上位ビットが0b1なら0t2で確定、0b0なら下位1ビットに応じて0t0か0t1かが決まります。
1trit, 2tritのいずれの場合でも最上位ビットが0なら残りのビットをエンコードする必要があり、1なら残りのビットは省略することができます。 最上位ビットが0の数を「小さい数」、1の数を「大きい数」と呼んで区別することにします。
大小による場合分け
B1, B2の2ブロックの大小の組み合わせは全部で4通りあり、B3は1tritなので3通りあります。 B3は00,01,10のいずれかにエンコードされるため、11に別の組み合わせを割り当てることでうまく8bitに収めることができます。
具体的には、B3をエンコードした値を0bXY、B1,B2をエンコードした値の下位3bitを0bEFG 0bBCDと書くことにすると、
| B2 | B1 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|
| S | S | X | Y | B | C | D | E | F | G |
| S | L | 1 | 1 | X | Y | 0 | B | C | D |
| L | S | 1 | 1 | X | Y | 1 | E | F | G |
| L | L | 1 | 1 | 1 | 1 | X | Y | 0 | 0 |
(ただし、S が小さい数、 L が大きい数。上位trit/bitを左に書いていることに注意)
とエンコードすればよいです。 デコード時には、上位ビットから読めば場合分けできます。
ここからさらに"よい"性質を持たせることを考えます。 例えば、上位3tritが0であるとわかっているようなときにエンコード・デコードを簡略化できるとうれしいです。 具体的には、0t00000から0t00022をエンコードした結果の下位4bitが0b0000から0b1000になっていると、この範囲のデコードが非常に単純になります。 今のエンコードでは0t22のときに0b11000000にエンコードされるので、下位ビットが0b1000とは異なっています。
実は、次のようにエンコードすることで実現できます。
小さい数の下位ビットをB1,B2,B3それぞれについて0bEFG 0bBCD 0bAと書くことにすると、
| B3 | B2 | B1 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|
| S | S | S | 0 | B | C | D | A | E | F | G |
| L | S | S | 1 | B | C | D | 0 | E | F | G |
| S | S | L | 1 | B | C | D | 1 | 0 | 0 | A |
| L | S | L | 1 | B | C | D | 1 | 0 | 1 | 0 |
| S | L | S | 1 | E | F | G | 1 | 1 | 0 | A |
| L | L | S | 1 | E | F | G | 1 | 1 | 1 | 0 |
| S | L | L | 1 | 0 | 0 | A | 1 | 0 | 1 | 1 |
| L | L | L | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
(S が小さい数、 L が大きい数)
実際に確認してみましょう。 まず、上位3trit以上が0のとき、B2,B3は0となるため、必ず小さい数となります。 表からB2,B3がLとなっている行を取り除いて、
| B1 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| S | 0 | B | C | D | A | E | F | G |
| L | 1 | B | C | D | 1 | 0 | 0 | A |
さらに、A,B,C,Dは0となるため、
| B1 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| S | 0 | 0 | 0 | 0 | 0 | E | F | G |
| L | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
下位4bitを見ると、確かに下位2tritであるB1を4bitにエンコードした結果と一致しています。また、上位bitは7bit目は3bit目をコピーし、あとは0埋めしたものになっています。
実は、このエンコーディングでは0t02122(=71)以下の値をエンコードすると、素直に2trit→4bit変換をして順にくっつけたものと下位7bitが一致します。 この範囲ではB3が0、B2が小さい数となるため、エンコード規則は次のように非常に単純になります。
| B1 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| S | 0 | B | C | D | 0 | E | F | G |
| L | 1 | B | C | D | 1 | 0 | 0 | 0 |
元ネタ
このDPTには「元ネタ」があります。10進数を2進数にエンコードするときに用いられるDPD(Densely Packed Decimal)です。 Wikipediaの記事にアルゴリズムの詳しい解説が載っています。
Densely packed decimal - Wikipedia
この記事の解説もWikipediaのDPDの解説を参考にさせていただきました。
実装
Rustにて実装したものがこちらになります。
https://github.com/primenumber/densely_packed_ternary
このリポジトリには、DPT以外にも他にいくつかのアルゴリズムの実装もおいてあります。 ぜひ使ってみてください(あとでドキュメント等を整備しつつcrates.ioにも上げておきます)。 それでは楽しい3値ライフを!
*1:長さが5の倍数でないときは0埋めしたり端数を別で持ったりすればよい
MN-Core Challenge #1 で優勝しました 【問題解説付】
2024/8/28 - 2024/9/23 に開催されたプログラミングコンテストMN-Core Challenge #1に参加し、なんと優勝することができました! この記事ではコンテストの振り返りと各問題に対する自分の解法の簡単な解説を行います。
MN-Coreについて
概要
MN-CoreシリーズはPreferred Networksが開発しているアクセラレータで、高いピーク性能・電力効率を実現するためかなり割り切った設計になっています。 数千個あるPEがすべて同期して動作する、条件分岐やループといった命令は存在しない、などの特徴により、動作がほぼすべて決定的*1という特徴があります。 ループや条件分岐がないため、繰り返し動作はその回数分だけ命令を並べることになります。 この特徴により、実行時間がほぼ命令数に比例することになります。逆に、命令数を減らせればそれだけ短時間で計算が完了することになります。
詳しいアーキテクチャ等については公式サイトをご覧ください。 以下では、アーキテクチャの概要だけ説明します。
木構造SIMDアーキテクチャ
MN-Core 2は全体に8個のL2B、各L2Bに8個のL1B、各L1Bに16個のMAB、各MABに4個のPEがある、という木構造をなしています。木構造の各階層で分配・結合・縮約・放送等の集団通信が行えるようになっていて*2、これによりPE-PE間、PE-DRAM間等の通信を行う設計になっています。
演算・転送の同時実行
各PEにはALU, MAUという二つの演算ユニットがあり、PE間にはL1BM, L2BMといった通信用ユニットがありますが、これらは同時に実行することができます。 いわゆるVLIWとなっており、これにより演算と転送のオーバーラップであったり、行列演算の裏でALUを動かして次の行列演算の準備をしたり、といったことが可能です。
サイクル方向・ワード方向SIMD
4096個のPEがすべて同じ命令を実行するという巨大なSIMD構造になっているというのはすでに述べましたが、MN-CoreのSIMD並列性はそれだけではありません。 まず、各演算ユニットは4サイクルの間同じ演算を実行し続けます。フォワーディングレジスタの値はちょうど4サイクル後に読めるので、1/4の周波数で4並列SIMDで動いているかのように扱うことができます*3。 また、各ALU/MAUはおおむね1サイクルに64bit幅分の演算を実行でき*4、32bit演算なら2並列、16bit演算なら4並列で演算することができます。
MABによる行列演算
MAB(4PE)単位で行列演算を行う演算器があり、行列の積和演算ができます。
| 精度 | スループット(FMA/cycle) |
|---|---|
| 倍精度 | 2 |
| 単精度 | 8 |
| 疑似単精度*5 | 16 |
| 半精度*6 | 64 |
ただし、ここでの各浮動小数点数はブロックフロート化という処理をあらかじめ行う必要があり、これにより仮数部の精度が若干落ちています。 疑似単精度や半精度の行列演算スループットはかなり高い(ベクトルFMAのそれぞれ2倍、4倍)ため、行列演算器をうまく活用できれば大幅な高速化が可能になります。
PEメモリ
複数種類のオンチップメモリがあり、各PEにはローカルメモリ(LM0,LM1),汎用レジスタ(GRF0,GRF1),Tレジスタ(T) 各MABには行列レジスタ(X, Y) 各L1BにはL1BM、各L2BにはL2BM、各グループにはPDMがあります。 PEにある複数種類のメモリは容量、レイテンシ、読み書きのタイミング制約などがそれぞれ異なるため、計算途中のデータをどのメモリに割り当てるかも重要なポイントとなります。
MN-Core Challenge #1
MN-Core Challenge #1 はなるべく少ない命令数で目的の計算を行うプログラミングコンテストとなります。通常のアルゴリズムやヒューリスティックのコンテストというよりは、コードゴルフやパズル的要素が強いものとなっています。 開催期間は約一か月間、問題数は練習問題やスコアに影響しないラスボス問を含めて20問となっており、かなりのボリュームでした。 前半がチュートリアル要素の強い問題、後半が複合的な問題、最後がラスボス問のFizzBuzzでした。 FizzBuzzは普通のプログラミング環境ではあまり難しいところはないですが、MN-Coreには整数の乗除算もバイト単位のメモリ読み書きもなく、ループができないのに6000個以上出力しなくてはならず、でもParは400行…というところから難易度を察することができると思います。
各問題簡易解説
ここからはコンテスト参加者等MN-Coreにある程度理解のある人に向けた解説となります。 自分が最初に全体の最短解を提出した問題(👑のある問題)と、コンテスト後に全体最短を更新できた問題だけ解説します。
スコアの説明
- 全体ベスト: コンテスト参加者の全提出中での最短行数
- 自己ベスト: 私の提出の最短行数、👑のあるものは、最短提出のなかで私の提出したコードがもっとも早くに提出されたことを示す。
Mul 7
- 全体ベスト: 6行
- 自己ベスト: 6行👑
問題概要
y[i] = x[i] * 7 (x[i]: ulong, i = 0, 1, ..., 15)
整数値に7を掛けて出力する。
解法
MN Core 2には整数乗算命令がない(!)ので、他の命令で代替する必要があります。
浮動小数点数の乗算はあるので、これを使うことにします。
浮動小数点数の乗算では非正規化数はサポートされていないので、正規化数になるようにALUで適当な指数ビットを含む上位ビットを付ける必要があります。
また、乗算後の結果を再び整数に直す必要がありますが、ここでftoi(浮動小数点数→整数変換命令)を使ってしまうと行数がかさんでしまうので、仮数部の下位ビットに乗算結果が来るようにいい感じの定数を乗算時に足します(積和演算命令があるのでこういうことができます)。
最後にマスクで下位16ビットだけを書き込むことで正答できます。
ここで登場する定数は指数部を作るための定数、乗算する数7.0(あるいはその2k倍)、FMA時に指数部を調整する定数の3つですが、前者2つは両方7.0、後者は-(7.02) + 7.0とすれば、即値命令1つとFMA命令1つで必要な定数を用意することができます。
下位ビットだけ取り出すマスクも生成する必要がありますが、ALUで上位ビットを16bit単位でのmaxをとるsmax命令を使えばよいです。
コーナーケースとして、入力値が0のときに下位ビットもマスクされ書き込まれなくなってしまいますが、0の7倍は0であり、結果を書き込むメモリはもともと0で初期化されているため、書き込まれなくても問題ありません。
imm i"0x40e00000" $ls64v smax $lm0v $aluf $omr1; fvfma -$aluf $aluf $aluf $lr72v smax $lm8v $ls64v $omr1; fvfma $aluf $ls64v $mauf $ln0v/$imr1 smax $lm16v $ls64v $omr1; fvfma $aluf $ls64v $lr72v $ln8v/$imr1 smax $lm24v $ls64v $omr1; fvfma $aluf $ls64v $lr72v $ln16v/$imr1 fvfma $aluf $ls64v $lr72v $ln24v/$imr1
Abs
- 全体ベスト: 13行
- 自己ベスト: 13行👑(単独ベスト)
問題概要
y[i] = |x[i]| (x[i]: int, i = 0, 1, ..., 87)
整数値が与えられるので、その絶対値を出力します。
解法
まず14行解から解説します。
答えはxが非負ならx、負なら-xとなります。-xを作るにはsubで0-xを計算すればよく、0は0初期化されているメモリを読めばよいです。
xを書き込むか-xを書き込むかを選択するためにALUのmax命令を使うことができます。
これにより正答できますが、ALUはsubでも使っているため、スループットを考えると22行が下限になります。
より短くするにはmaxをなるべく使わずに済む方法を考える必要があります。
書き込みマスク機能を使うと、対象のメモリに書き込むか書き込まないかを動的に切り替えることができます。
この問題では、まず-xを書き込んだ後、xが非負の時のみxを書き込めば目的が達成できます。
このマスクを作るのにMAUを使うことができます。整数値を無理やり浮動小数点数だと思うと、入力は32bit値でなので、非負のときは0.0、負の時は-infとなります。MAUの生成するマスクは符号ビットを反転したものになるので、これでxの書き込みをマスクすればよいです。
書き込むときにALUを使うこともできますが、さらによい方法としてL1BMを使う方法があります。
l1bmdを使うことで各PEでサイクルあたり1長語を読み書きできます。さらに、L1BM折り返しレジスタだけを使うときは、読み込みと書き込みの同時実行が可能で、これでxをマスク付きで書き込むことができます。
しかし、subとl1bmdで同時にLM1に書き込むことはできないので、片方はGRFにいったんためておき、あとでpassaによる2長語書き込みをすることにします。
このとき、最後のl1bmdでLM1に書き込まないようにすることで、すべてのsubを終えてすぐ2長語書き込みを開始することができ、14行が達成できます。
fvpassa $lm0v $omr1; isub $ls256 $lm0v $ls0v; l1bmd $lm0v $lbi fvpassa $lm8v $omr1; isub $ls256 $lm8v $ln8v; l1bmd $lm8v $lbi; l1bmd $lbi $ls0v/$imr1 fvpassa $lm16v $omr1; isub $ls256 $lm16v $ls16v; l1bmd $lm16v $lbi; l1bmd $lbi $ln8v/$imr1 fvpassa $lm24v $omr1; isub $ls256 $lm24v $ln24v; l1bmd $lm24v $lbi; l1bmd $lbi $ls16v/$imr1 fvpassa $lm32v $omr1; isub $ls256 $lm32v $ls32v; l1bmd $lm32v $lbi; l1bmd $lbi $ln24v/$imr1 fvpassa $lm40v $omr1; isub $ls256 $lm40v $ln40v; l1bmd $lm40v $lbi; l1bmd $lbi $ls32v/$imr1 fvpassa $lm48v $omr1; isub $ls256 $lm48v $ls48v; l1bmd $lm48v $lbi; l1bmd $lbi $ln40v/$imr1 fvpassa $lm56v $omr1; isub $ls256 $lm56v $ln56v; l1bmd $lm56v $lbi; l1bmd $lbi $ls48v/$imr1 fvpassa $lm64v $omr1; isub $ls256 $lm64v $ls64v; l1bmd $lm64v $lbi; l1bmd $lbi $ln56v/$imr1 fvpassa $lm72v $omr1; isub $ls256 $lm72v $ln72v; l1bmd $lm72v $lbi; l1bmd $lbi $ls64v/$imr1 fvpassa $lm80v $omr1; isub $ls256 $lm80v $ls80v; l1bmd $lm80v $lbi; l1bmd $lbi $ln72v/$imr1 lpassa $lls[0,4,16,20] $lln[0,4,16,20]; l1bmd $lbi $ls80v/$imr1 lpassa $lls[32,36,48,52] $lln[32,36,48,52] lpassa $lls[64,68,80,84] $lln[64,68,80,84]
さて、続いては13行解の解説をします。
subはこれ以上減らせないため、なんとかしてpassaを減らす必要があります。この解法ではALUの2長語動作を活用します。
subのような1長語動作する命令の第一オペランドに2長語の入力を与えると、ALUの2長語の出力のLSB側*71長語は第一オペランドのLSB側1長語となります。
これを活用することで、すでに計算した結果をsubの第一オペランドのLSB側においておき、LM1に2長語書き込みをすることで、結果の書き込みを2長語で行えます。
ただ、2長語は連続している必要があるので、いつでも2長語で書き込める訳ではなく、最後にsubで書き込み切れなかった4長語分をpassaで書き込むのに1ステップ必要となってしまいました。
うまくやることで12行になる可能性もあると思いますが、現時点では達成できていません。
fvpassa $lm0v $omr1; isub $ls256 $lm0v $ln0v; l1bmd $lm0v $lbi fvpassa $lm10v4 $omr2; isub $ls256 $lm10v4 $lr10v4; l1bmd $lm10v4 $lbi; l1bmd $lbi $ln0v/$imr1 fvpassa $lm24v $omr3; isub $ls256 $lm24v $ln24v; l1bmd $lm24v $lbi; l1bmd $lbi $lr10v4/$imr2 fvpassa $lm34v4 $omr4; isub $ls256 $lm34v4 $lr34v4; l1bmd $lm34v4 $lbi; l1bmd $lbi $ln24v/$imr3 fvpassa $llm8v $omr5; isub $llr8v $llm8v $lln8v; l1bmd $llm8v $lbi; l1bmd $lbi $lr34v4/$imr4 fvpassa $lm50v4 $omr6; isub $ls256 $lm50v4 $lr50v4; l1bmd $lm50v4 $lbi; l1bmd $lbi $ln8v4/$imr5 fvpassa $llm32v $omr7; isub $llr32v $llm32v $lln32v; l1bmd $llm32v $lbi; l1bmd $lbi $lr50v4/$imr6 fvpassa $lm66v4 $omr8; isub $ls256 $lm66v4 $lr66v4; l1bmd $lm66v4 $lbi; l1bmd $lbi $ln32v4/$imr7 fvpassa $llm48v $omr9; isub $llr48v $llm48v $lln48v; l1bmd $llm48v $lbi; l1bmd $lbi $lr66v4/$imr8 fvpassa $lm80v $omr10; isub $ls256 $lm80v $lr80v; l1bmd $lm80v $lbi; l1bmd $lbi $ln48v4/$imr9 fvpassa $llm64v $omr11; isub $llr64v $llm64v $lln64v; l1bmd $llm64v $lbi; l1bmd $lbi $lr80v/$imr10 l1bmd $lbi $ln64v4/$imr11 ipassa $lr80v $ln80v
FAM 8
- 全体ベスト: 15行
- 自己ベスト: 15行(コンテスト後に14行解を発見)
問題概要
y[i] = (x[i] + 8) × 8 (x[i]: float, i = 0, 1, ..., 127) 8を足した後8倍した値を出力します。
解法
(x + 8.0) × 8.0 = x × 8.0 + 64.0なので、8.0と64.0を用意すればfmaで計算できます。fvfmaを使うことで18行が達成できます。
ここからさらに縮めることを考えます。
入力を半精度に変換すると精度が足りないため、hvfmaをそのまま使うことはできません。
fvfmaをしている間空いているALUを使いたいですが、ALUで浮動小数点数の足し算を行うことは困難です*8。
さあ困った…といったところですが半精度とALU利用の合わせ技で解決できます。
MAUの半精度ベクトル演算では、half(長語) * half(長語) + float(2長語)の結果をfloat(2長語)で得ることができます*9。
乗算や加算もFMAを利用して実現されており、半精度加算はhalf(長語) + float(2長語)の結果がfloat(2長語)で得られます。
8.0は半精度でもロスなく表現できるため、8.0 + x[i]はhvaddで2長語演算が可能です。
あとはALUで8倍ができればよく、これは指数部に3を足すことで実現できます。0~1の値に8.0を足しているので指数部は8の指数部と等しくなっており、0やinfなどに対する特別な考慮は必要ありません。
必要な3個の定数0x01800000*10、8.0、64.0はどれか2つを持っていれば、もう一つはすぐに作ることができます。
MAUとALUでできた結果を同時にLM1に書き込むことはできないため、片方はいったんためておき最後にpassaで2長語書き込みをします。
これで16行解を作ることができました。
imm f"8.0" $t imm i"0x01800000" $ls128v; fvmul $aluf $aluf $nowrite hvadd $tr $llm0v $llr0v; l1bmd $mauf $lbi; hvadd $tr $llm16v $llr16v; iadd $ls128v $mauf $ln0v4; hvadd $tr $llm32v $llr32v; iadd $ls128v $lr2v4 $ln2v4; hvadd $tr $llm48v $llr48v; iadd $ls128v $lr16v $ln16v; hvadd $tr $llm64v $llr64v; iadd $ls128v $lr24v $ln24v; l1bmd $lbi $ls256v; noforward; fvfma $lm80v $t $lbf $ln80v; iadd $ls128v $lr32v $ls32v; noforward; fvfma $lm88v $t $lbf $ln88v; iadd $ls128v $lr40v $ls40v; noforward; fvfma $lm96v $t $lbf $ln96v; iadd $ls128v $lr48v $ls48v; noforward; fvfma $lm104v $t $lbf $ln104v; iadd $ls128v $lr56v $ls56v; noforward; fvfma $lm112v $t $lbf $ln112v; iadd $ls128v $lr64v $ls64v; noforward; fvfma $lm120v $t $lbf $ln120v; iadd $ls128v $lr72v $ls72v; ipassa $lls32v $lln32v; ipassa $lls48v $lln48v; ipassa $lls64v $lln64v;
15行解はAbs同様addに2長語入出力をさせたり、fvfmaの結果をfreluで2長語にパックしたりすることで実現できます。
imm f"8.0" $t imm i"0x01800000" $lr128v $ls128v hvadd $tr $llm0v $llr0v; iadd $aluf $t $ls136v; hvadd $tr $llm16v $llr16v; iadd $ls128v $mauf $ln0v4; l1bmd $aluf $lbi; hvadd $tr $llm32v $llr32v; iadd $ls128v $lr2v4 $ln2v4; hvadd $tr $llm48v $llr48v; iadd $ls128v $lr16v $ln16v; l1bmd $lbi $ls256v; noforward; fvfma $lm64v $t $lbf $ln64v; iadd $ls128v $lr32v $ls32v; noforward; fvfma $lm72v $t $lbf $ln72v; iadd $ls128v $lr40v $ls40v; noforward; fvfma $lm80v $t $lbf $ln80v; iadd $ls128v $lr56v $ls56v; noforward; fvfma $lm88v $t $lbf $ln88v; iadd $ls128v $lr48v $ls48v; noforward; fvfma $lm96v $t $lbf $ls96v; iadd $ls128v $lr24v $ln24v; noforward; fvfma $lm104v $t $lbf $ls104v; ipassa $lls32v $lln32v; noforward; fvfma $lm114v4 $t $lbf $ls114v4; ipassa $lls48v $lln48v; fvfma $lm112v4 $t $lbf $nowrite; ipassa $lls96v $lln96v; frelu $lls112v $mauf $lln112v;
コンテスト後、14行解を発見しました。
ALU/MAUのバランスを変えたり、命令スケジューリングを工夫したりしてなんとか実現できました。
ALUで計算した結果を2長語書き込みするタイミングをhvaddの裏にすることで、fvfmaがLM1に書くタイミングとiaddがLM1に書くタイミングがなるべくぶつからないようにすることができます。
imm f"8.0" $t imm i"0x01800000" $lr128v4 $ls128v4 hvadd $tr $llm0v $llr0v; iadd $aluf $t $nowrite; l1bmd $aluf $lbi hvadd $tr $llm16v $llr16v; iadd $ls128v4 $mauf $ln0v4; l1bmd $aluf $lb0; l1bmd $lbi $ls144v4 hvadd $tr $llm32v $llr32v; iadd $ls128v4 $lr2v4 $ln2v4; l1bmd $lbi $nowrite; noforward; fvfma $lm96v $t $lbf $ln96v; iadd $ls128v4 $lr18v4 $ls130v4; noforward; fvfma $lm104v $t $lbf $ln104v; iadd $ls128v4 $lr34v4 $ls146v4; noforward; hvadd $tr $llm48v $llr48v; iadd $lls128v $lr16v4 $lln16v; noforward; hvadd $tr $llm64v $llr64v; iadd $lls144v $lr32v4 $lln32v; noforward; fvfma $lm80v $t $lbf $ln80v; iadd $ls128v4 $lr50v4 $ls130v4; noforward; fvfma $lm88v $t $lbf $ln88v; iadd $ls128v4 $lr66v4 $ls146v4; noforward; fvfma $lm114v4 $t $lbf $ls114v4; iadd $lls128v4 $lr48v4 $lln48v fvfma $lm112v4 $t $lbf $nowrite; iadd $lls144v4 $lr64v4 $lln64v frelu $lls112v $mauf $lln112v;
FMul 2
- 全体ベスト: 9行
- 自己ベスト: 9行👑(単独ベスト)
問題概要
y[i] = x[i] * 2 (x[i]: half, i = 0, 1, ..., 191) 入力を2倍した値を出力します。
解法
定数2.0を用意してx * 2.0を計算しなくても、x + xで2倍することができます。 これで12行解を作ることができます。
MAUだけではこれ以上は難しいので、ALUも活用することを考えます。マニュアルをよく読むとilreludという、第一引数がの符号ビットが1なら第二引数の指数部に1を足す(≒2倍する)命令があるので、これを使います。この問題は1e-9までの絶対誤差が許されるので、0のときに2倍の0でなく最小の正規化数2^-30になってしまうことは問題ありません。
残念なことに、ilreludの第一オペランド(のMSB側1長語)は符号ビットが1でなければならないので、2長語でLM0から読みつつ計算はできません。
passaで2長語読み込みしてGRFに書き込みつつ、同時にMSB側長語はMAUで計算するのを4ステップ行うと、GRFに格納済みでまだ未計算の部分が4ステップ分できるので、これをilreludで計算しつつ、MAUは新たにLM0から読んですぐ計算するのを同時に行うことができます。
最後にMAUがLM1に書いている間にALUで計算してためておいた部分をpassaでLM1に転送すれば、10行で解くことができます。
spassa $llm0v $llr0v; hvaddr $llm0v $llm0ve $lln0v spassa $llm16v $llr16v; hvaddr $llm16v $llm16ve $lln16v spassa $llm32v $llr32v; hvaddr $llm32v $llm32ve $lln32v spassa $llm48v $lls48v; hvaddr $lr2v4 $lr2v4e $ln2v4 hilrelud $msb1 $aluf $lr48v4; hvaddr $lm80v $lm80ve $ln80v hilrelud $msb1 $ls50v4 $lr50v4; hvaddr $lm88v $lm88ve $ln88v hilrelud $msb1 $lm64v $ls64v; hvaddr $lr18v4 $lr18v4e $ln18v4 hilrelud $msb1 $lm72v $ls72v; hvaddr $lr34v4 $lr34v4e $ln34v4 spassa $llr48v $lln48v; spassa $lls64v $lln64v;
9行解はilreludで2長語書き込みをなんとか実現させることで到達できます。
先ほど述べた通り、ilreludの第一オペランドのMSB側1長語の符号ビットは1になっている必要があります。したがって、MSB側長語には符号ビットが1のデータを、LSB側長語にはすでに計算済みの結果で、MSB側の計算結果といっしょにLM1に書き込みたい内容を入れておく必要があります。
ilreludで第一オペランドに$msb1を指定し、これを2長語でGRFに書き込んでおくと、LSB側長語は符号ビットが1のデータで埋まったデータができます。
しかし、2長語書き込み時にはMSB側に符号ビットが1のデータが入っている必要があるため、何らかの方法でさらに転送する必要があります。
ALUとMAUはすでにフル稼働なので、l1bmdを使って転送します。
必要な計算を行いつつ2長語書き込みの準備を行うのは簡単ではないですが、なんとか実現することができ、これで9行解が完成しました。
hpassa $llm0v $llr0v; hvaddr $llm0v $llm0ve $ln0v4 hpassa $llm16v $llr16v; hvaddr $llm16v $llm16ve $ln16v4 hilrelud $msb1 $lr2v4 $ln2v4 $lls256v; hvaddr $lm66v4 $lm66v4e $lr66v4 hpassa $llm32v $llr32v; hvaddr $llm32v $llm32ve $ln32v4; hilrelud $msb1 $lr18v4 $ln18v4; hvaddr $lm50v4 $lm50v4e $ls50v4; l1bmd $ls258v4 $lbi hilrelud $msb1 $lr34v4 $ln34v4; hvaddr $lm48v4 $lm48v4e $nowrite; l1bmd $lbi $lr64v4 $ls80v4 hrelu $lls48v $mauf $lln48v; hvaddr $lm82v4 $lm82v4e $ls82v4 hilrelud $llr64v $lm64v4 $lln64v hilrelud $lls80v $lm80v4 $lln80v
Lesseq
- 全体ベスト: 4行
- 自己ベスト: 4行
x[i] >= 1なら∞、そうでないなら0をy[i]に書き込む。 (ただし、
の倍数)
👑でもなんでもないため、解説は端折ります*11。 本質は実は半精度が使えること、そしてx*x - xの符号で1以上かどうか判定できることです。 わかりやすい解説があれば後でここにリンクを張ろうと思います。
Transpose
- 全体ベスト: 10行
- 自己ベスト: 10行👑
問題概要
doubleの8行8列の行列を転置する。
解法
毎サイクル1長語転送すると16行で解くことができます。 これより縮めるためには2長語転送をする必要があります。
12行解は次のようにして作ることができます。
ALUのpassaで2長語で読み込み、MSB側1長語は直接LM1に書き込みつつ、GRFに2長語で書き込みます。
8ステップで行列全体がGRFに格納されます。
0, 2, 4, 6行目の書き込みが完了しており、残りの1, 3, 5, 7行目を2長語書き込みで書き込めればよいことになります。
しかし、GRFに読み込んでそのままでは、書き込みたい内容が連続したアドレスに配置されていません。
ここで、MAUのdvpassaがALUの命令と同時実行できることを利用して、ALUによる2長語読み込みの裏でせっせと長語単位での並べ替えを行います。
最後の2長語書き込みでほしい順に読み込みや並べ替えを行うことで、12行解が完成します。
lpassa $llm0v $ln0v32 $llr0v lpassa $llm16v $ln2v32 $llr16v lpassa $llm32v $ln4v32 $llr32v; dvpassa $lr2v4 $ls16v32 lpassa $llm48v $ln6v32 $llr48v; dvpassa $lr18v4 $ls18v32 lpassa $llm64v $ln8v32 $llr64v; dvpassa $lr34v4 $ls20v32 lpassa $llm80v $ln10v32 $llr80v; dvpassa $lr50v4 $ls22v32 lpassa $llm96v $ln12v32 $llr96v; dvpassa $lr66v4 $ls24v32 lpassa $llm112v $ln14v32 $llr112v; dvpassa $lr82v4 $ls26v32 lpassa $lls16v32 $lln16v32; dvpassa $lr98v4 $ls28v32 lpassa $lls20v32 $lln20v32; dvpassa $lr114v4 $ls30v32 lpassa $lls24v32 $lln24v32 lpassa $lls28v32 $lln28v32
ここから10行解の解説をしていきます。
入力の制約がであることから、この値を
reluの第一オペランドに与えると、演算結果は第二オペランドの値になります。
ALUの第一オペランドに2長語で入力すると、reluは1長語動作なので、MSB側が第二オペランドから、LSB側が第一オペランドから取られた2長語が得られます。
これを利用して、4×4の転置を行うことを考えます。
| row\col | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | eM0 | eL0 | eM1 | eL1 |
| 1 | oM0 | oL0 | oM1 | oL1 |
| 2 | eM2 | eL2 | eM3 | eL3 |
| 3 | oM2 | oL2 | oM3 | oL3 |
表: 転置前の4x4行列。各セルの表記はそれぞれe:偶数行目の読み込み, o:奇数行目の読み込み, M:MSB側長語, L:LSB側長語, 0~3: サイクル数を表している。
2長語で偶数行目を読み込み、MSB側1長語は直接LM1に書き込みつつ、GRFに格納します。 次に2長語で奇数行目を読みつつ、さっき読み込んだ偶数行目のLSB側長語をreluの第二引数に与えます。
MSB側が偶数行目のLSB側、LSB側が奇数行目のLSB側となっており、これは転置先で連続した2長語になるので、LM1に2長語書き込みができます。
同時にdvpassaでreluで拾われなかった奇数行目のMSB側をGRFに書き込みます。
最後にGRFに書き込んだ奇数行目のMSB側をLM1に書き込みます。
GRFの読み書き制約から、各行の間にnopを挟む必要がありますが、これで4x4の転置を3行+2nopで行うことができました。
nopの代わりに別の4x4行列を転置することにすれば、4x8行列を6行で転置できます。
lpassa $llm[0,4,32,36] $ln[0,32,4,36] $llr0v lpassa $llm[8,12,40,44] $ln[64,96,68,100] $llr16v drelu $llm[16,20,48,52] $lr2v4 $lln[16,48,20,52]; dvpassa $llm[16,20,48,52] $ls0v drelu $llm[24,28,56,60] $lr18v4 $lln[80,112,84,116]; dvpassa $llm[24,28,56,60] $ls8v dvpassa $ls[0,4,2,6] $ln[2,6,34,38]; dvpassa $ls[8,12,10,14] $ln[66,70,98,102];
4x8転置の最後の2行では、LM0からの読み込みを行っていないので、この間に別の4x8行列の偶数行目を読み込むことにします。
LM1への書き込みはこのタイミングではポートが埋まっていてできないので、あとでやることにします。
のこり4行では、reluを使って偶数行目のLSB側と奇数行目のMSB側、偶数行目のMSB側と奇数行目のLSB側をそれぞれくっつけることで、転置しつつ2長語で書き込むことができます。
全体を通すと以下のようになります。
lpassa $llm[0,4,32,36] $ln[0,32,4,36] $llr0v lpassa $llm[8,12,40,44] $ln[64,96,68,100] $llr16v drelu $llm[16,20,48,52] $lr2v4 $lln[16,48,20,52]; dvpassa $llm[16,20,48,52] $ls0v drelu $llm[24,28,56,60] $lr18v4 $lln[80,112,84,116]; dvpassa $llm[24,28,56,60] $ls8v lpassa $llm[64,68,96,100] $llr80v $lls80v; dvpassa $ls[0,4,2,6] $ln[2,6,34,38]; lpassa $llm[72,76,104,108] $llr96v $lls96v; dvpassa $ls[8,12,10,14] $ln[66,70,98,102]; drelu $llm[80,84,112,116] $lr82v4 $lln[24,56,28,60]; dvpassa $llm[80,84,112,116] $ls18v4 drelu $llm[88,92,120,124] $lr98v4 $lln[88,120,92,124]; dvpassa $llm[88,92,120,124] $ls34v4 drelu $lls16v $lr80v4 $lln[8,40,12,44]; drelu $lls32v $lr96v4 $lln[72,104,76,108];
Gather
- 全体ベスト: 6行
- 自己ベスト: 6行
問題概要: インデックスが格納された配列が与えられるので、そのインデックスで別の配列を間接参照した先の値を出力する。
解説省略
Square Sum
- 全体ベスト: 10行
- 自己ベスト: 10行
問題概要: 入力の二乗和を出力する。
解説省略
Convert Endian
- 全体ベスト: 3行
- 自己ベスト: 3行
問題概要: long値のバイト順を反転する。
わかりやすい解説:
Convert Endianの王冠を最後まで守り抜けました!#mncore pic.twitter.com/I7abheN6u1
— kikx (@kikx) 2024年9月23日
Mod 3
- 全体ベスト: 9行
- 自己ベスト: 11行
スコアに加算される問題で唯一最短・最短タイを取れなかった問題。 積和算とbitwise andを用いてmod3を取る方法があるらしく、知らなかったのであとで確認することにします。
Matrix Square
- 全体ベスト: 10行
- 自己ベスト: 10行
11行は最早で出せて、あとちょっとで10行だったのでもうちょっと粘るべきでした。 半精度を使えることに気づければ短くかつシンプルになる。
Contains
- 全体ベスト: 20行
- 自己ベスト: 20行👑
問題概要
配列Aの各要素が、配列Bの中に含まれているかをぞれぞれ0/1で出力する。 配列AはMAB間、PE間で放送されているが、配列BはMAB間、PE間に分散して配置されている。
解法
Bの値の範囲が1000以下と小さいので、LM0の空いている場所にTレジスタ間接参照で定数値を書き込み、頻度配列(存在判定だけできればよいので、実際には0/1だけ持つ)を作ります。 Aの値でもTレジスタ間接参照を行って、PE内で対応する値がBに含まれていれば書き込んだ定数値、なければ0が得られます。 これをL1B以下64PE間で論理ORを取ったものが答えになります。
L1B以下MAB間の縮約にはl1bmrior(論理OR縮約)が使えるので高速な一方で、MAB内のPE間縮約はmsl/msrを使うとかなりステップ数が必要になってしまいます。
しかし、あとでl1bmriorで縮約することを考えると、0/非0だけわかれば十分で、論理ORではなく加算縮約を行っても問題ありません。
行列レジスタを全部1.0で埋めておけば、半精度行列積でPE間の半精度値の加算縮約ができます。
行列演算をするとき、あらかじめブロックフロート化を行う必要がありますが、そもそも用意する定数値をブロックフロート化済みの値にすれば、動的に変換する必要はありません。 あらかじめブロックフロート化した定数を用意する方法は半精度行列積でのみ可能です。 半精度のみ、指数部が共通指数部以外に0が許されているという仕様があるためで、間接参照で0を拾ったときにエラーにならずに0.0として扱われます。
これにより20行で解くことができました。
lpassa $ln0v $t; l1bmm@0 $llm0v $llbi imm h"1.5" $llr4v; l1bmm $llbi $lls0v; fvpassa $aluf $mt1024; lpassa $ln8v $t; hbfn/9 $llr4v $llr24v hvpassa $r4 $mt1024; lpassa $ln16v $t hmwrite $llr24 $lx0 hvpassa $r4 $mt1024; lpassa $ln24v $t nop hvpassa $r4 $mt1024; lpassa $ls0v $t nop linc $lr96v $ls96v;l1bmd $ls8v $lbi hmmul $lx $mt1024 $r0v; l1bmd $lbi $t l1bmd $lm16v $lbi hmmul $lx $mt1024 $r4v; l1bmd $lbi $t l1bmd $lm24v $lbi hmmul $lx $mt1024 $r16v; l1bmrior $lr0v $lbi; l1bmd $lbi $t l1bmm $lbi $n33v4 hmmul $lx $mt1024 $r20v; l1bmrior $r16v $lbi; land $lbf $ls96 $ln34v4 l1bmrior $mauf $lbi; l1bmm $lbi $n49v2 l1bmm $lbi $n57v2
Count Up
- 全体ベスト: 26行
- 自己ベスト: 26行👑
問題概要
1~32768までの数値を順に1単語に1つ入れ、DRAMに格納します。
解法
各PEでは$peid $l1bid $l2bidなどをうまいことマスクしたりシフトした後足し合わせる必要があります。小さな自然数を即値として使いたいですが、そのために毎回immを使わなくて済む方法として、$peidをl1bmdでL1BMに送り、それをl1bmpで各PEに放送するテクニックがあります。これにより0~15までの自然数を比較的少ない命令数でメモリに格納することができました。
$peid $l1bid $l2bidをGRF0にあらかじめ格納しておくと、あとからそれらを$lr[x,y,z,w]の形で1ステップに最大4個参照できます。さらにさっき作った自然数をGRF1に入れておけば、それぞれに個別にマスクを掛けたりシフトしたりできます。
あとはサイクル方向のreduceをすればほぼ完成で、1-indexになるようにインクリメントしたりすれば完成です。
一度に4長語分作らなくてもスループット的には間に合うので、最初の1長語だけできたらすぐにl1bmdを開始し、あとは増分を足しつつl1bmdを何度も行っていきます。
L1BM→L2BM間の転送は結合縮約命令を使いました。後述するL2BM→PDM結合転送と転送単位をそろえられるメリットがあります。これにより各L1BMから1サイクル当たり16長語読みつつ、2つのL1B間で縮約演算を行ったものを4グループ分結合をして、L2BMには64長語/サイクルで書き込めます。 縮約演算にはmin/maxを指定することで、値にL1BID(をシフトしたもの)が入っていればL1BIDの小さいほう/大きいほうから選択的に転送することができます*12。
L2BM→PDM結合命令を使うことで、各L2BMからのデータを結合することができます*13。それをPDM→DRAM間単独個別転送命令でDRAMに送ればよいです。
PFN社内最短解はこれより3行も短いそうです*14。いったいどうやったんでしょうか…
ipassa $peid $lr68 ipassa $mabid $lr72; l1bmd $aluf $lb0 ipassa $l2bid $lr74 ipackbit $l1bid $ls128 $lr76 iinc $lr128 $t; l1bmp $llb8 $lls16v; # 8,C,9,D,A,E,B,F linc $aluf $lr80; l1bmp $llb0 $lls0v # 0,4,1,5,2,6,3,7 iand $lr[72,76,68,74] $ls[18,18,30,30] $lr96v; l1bmriiadd $t $lbi # [mabid_h,l1bid_h<<1,peid,l2bid] & [0xc,0xc,0xf,0xf] ilsl $aluf $ls[16,10,4,6] $lr256v; l1bmm $lbi $nowrite # [mabid_h,l1bid_h<<1,peid,l2bid] << [8,6,1,5] iadd $aluf $lr[80,80,80,256] $nowrite; l1bmriiadd $lbf $lbi iadd $aluf $lr[258,260,262,258] $nowrite; l1bmm $lbi $nowrite iadd $aluf $lr[260,262,256,260] $ls64v; l1bmriiadd $lbf $lbi iadd $aluf $lr[262,256,258,80] $nowrite; l1bmm $lbi $ls32/1000 iadd $lbf $aluf $nowrite; l1bmd $aluf $lb0 iadd $ls32 $aluf $nowrite; l1bmd $aluf $lb64 iadd $ls32 $aluf $nowrite; l1bmd $aluf $lb128 iadd $ls32 $aluf $nowrite; l1bmd $aluf $lb192; l2bmr2fmin $lb0 $lc0 iadd $ls32 $aluf $nowrite; l1bmd $aluf $lb256; l2bmr2fmin $lb64 $lc256 iadd $ls32 $aluf $nowrite; l1bmd $aluf $lb320; l2bmr2fmin $lb128 $lc512 iadd $ls32 $aluf $nowrite; l1bmd $aluf $lb384; l2bmr2fmin $lb192 $lc768 l1bmd $aluf $lb448; l2bmr2fmin $lb256 $lc1024 l2bmr2fmin $lb320 $lc1280 l2bmr2fmin $lb384 $lc1536 l2bmr2fmin $lb448 $lc1792 nop mvd/n2048 $lc0 $p0@0 mvp/n16384 $p0@0 $d0@0
Transpose MAB
- 全体ベスト: 15行
- 自己ベスト: 15行👑(単独ベスト)
問題概要
MAB間に1列ずつ格納された行列を転置する。 PE間では同じ値が放送されている。
解法
まず18行解法を解説します。
l1bmdにはmabdiffと呼ばれる機能があり、l1bmdで結合→分配した際に、転送先のMABを自分自身ではなく、別のMAB番号のMABにすることができます。
番号をずらす大きさは定数で指定し、ずらした先の番号が16以上や0未満の場合はmod 16したMAB番号のところに送られます。
この機能を利用し、1つ先のMABへ転送、2つ先のMABへ転送、…、15個先のMABへ転送と15回の転送を行うことにします。
しかし、0番MABからk個先のMABに渡したいのはk番目の値ですが、i番目のMABからk個先のMABに渡したいのは番目の値で、MAB番号ごとに送りたい対象のインデックスは異なります。
送り先のインデックスも同様にMAB番号ごとに異なります。
具体的には、i番MABにk個前のMABから送られてきた値の格納先のインデックスは
となります。
Tレジスタ間接参照を使えばMABごとに異なるインデックスを使うことはできます。 しかし、インデックスは単純な足し算ではなくmod演算が入っていて、かつ転送ごとに異なる値kに依存しています。 そのため、Tレジスタ等で間接参照するためには、値の設定時に毎回modを取る必要があります*15。 Tレジスタを毎回書き換えると、そのたびに1ステップ待たなくてはならず、15回の転送に最低でも31ステップかかってしまいます。
よく観察すると、modを取る前の値i+kは高々15+15=30なので、modを取るとそのままの値か16引いた値になります。
そこで、i+kとi+k-16の両方をl1bmdで転送してしまいます。転送先でもi-kとi-k+16の両方に書き込めばうまくいきます。
実はi+kが16以上になることと、k個先のMABでi-kが0以上になることは同値なので、i+kの転送先でのアドレスはi-k+16、i+k-16の転送先でのアドレスはi-kとなります。したがって、マスク等でどちらの値を書き込めばいいか等を選択する必要はありません。
アドレスのオフセットの設定方法ですが、LM1への書き込みアドレスのオフセットは、Tレジスタは使えないためベースアドレスレジスタを使う必要があります。
一方、LM0からの読み込みは、ベースアドレスレジスタへの書き込み後2ステップ開けなければならないので、1ステップ開ければよいTレジスタ間接参照の方がお得です。
最後に、自分自身に転送するデータはlpassa $lmt0 $ln0で送れますが、最初のl1bmdの未使用の2サイクルのLM0読み込みオフセットを0にして、同時にpassaを行えば無駄なく転送ができます。
これで18行解法ができました。
ipackbit $mabid $ls0 $t $nb nop ipassa $lmt[0,0,2,4066] $ln0/1000; l1bmd+1 $lmt[0,0,2,4066] $lbi l1bmd+2 $lmt[4,4,4,4068] $lbi; l1bmd+1 $lbi $ln[4094,4094,4094,30] l1bmd+3 $lmt[6,6,6,4070] $lbi; l1bmd+2 $lbi $ln[4092,4092,4092,28] l1bmd+4 $lmt[8,8,8,4072] $lbi; l1bmd+3 $lbi $ln[4090,4090,4090,26] l1bmd+5 $lmt[10,10,10,4074] $lbi; l1bmd+4 $lbi $ln[4088,4088,4088,24] l1bmd+6 $lmt[12,12,12,4076] $lbi; l1bmd+5 $lbi $ln[4086,4086,4086,22] l1bmd+7 $lmt[14,14,14,4078] $lbi; l1bmd+6 $lbi $ln[4084,4084,4084,20] l1bmd+8 $lmt[16,16,16,4080] $lbi; l1bmd+7 $lbi $ln[4082,4082,4082,18] l1bmd+9 $lmt[18,18,18,4082] $lbi; l1bmd+8 $lbi $ln[4080,4080,4080,16] l1bmd+10 $lmt[20,20,20,4084] $lbi; l1bmd+9 $lbi $ln[4078,4078,4078,14] l1bmd+11 $lmt[22,22,22,4086] $lbi; l1bmd+10 $lbi $ln[4076,4076,4076,12] l1bmd+12 $lmt[24,24,24,4088] $lbi; l1bmd+11 $lbi $ln[4074,4074,4074,10] l1bmd+13 $lmt[26,26,26,4090] $lbi; l1bmd+12 $lbi $ln[4072,4072,4072,8] l1bmd+14 $lmt[28,28,28,4092] $lbi; l1bmd+13 $lbi $ln[4070,4070,4070,6] l1bmd+15 $lmt[30,30,30,4094] $lbi; l1bmd+14 $lbi $ln[4068,4068,4068,4] l1bmd+15 $lbi $ln[4066,4066,4066,2]
15行解法では、18行解法で余っていたl1bmdの2サイクルを活用します。
折り返しレジスタにはmabdiffなしの場合と同じ値が書き込まれ、折り返し時にmabdiff分だけずらす処理が行われます*16。おかげで結合と分配でそれぞれずらされて2倍ずれる事態を回避できます。
一方、L1BMに書いた値はmabdiff分ずらした状態で格納されます。L1BMからの読み込み時にもmabdiffが有効なため、うっかりすると2倍ずらしてしまいますが、今回は結合と分配でそれぞれずれを指定できることを活用します。
l1bmd+1で1個先に送るデータに加えて9個先に送りたいデータをL1BMに格納し、l1bmd+2で2個先に送るデータに加えて10個先に送るデータを格納します。
うまいことL1BMに格納するアドレスを工夫すると、あとでl1bmd+8でL1BMから読んでくれば、1個ずれた9個先に送りたいデータと、2個ずれた10個先に送りたいデータが8個ずれてやってくるので、結果として9個、10個先のMABに転送したことになります。
l1bmd+1で18行解法の要領で自分自身と1個先のMABに転送します。
l1bmd+2~7の間は折り返しレジスタで転送しつつ、+10~+15分のデータをL1BMに書き込みます。l1bmd+8~9はハザードの回避のため折り返しレジスタだけを読み書きし、最後にl1bmd+8でL1BMから読むことで1ステップで2種類のmabdiff({+10,+11}, {+12, +13}, {+14, +15})に対して転送ができます。
l1bmdの数を3回減らすことができ、これで15行解法の完成です。
ipackbit $mabid $ls0 $t $nb; nop l1bmd+1 $lmt[2,4066,0,0] $lbi; dvpassa $lmt[2,4066,0,0] $ln0/0010 l1bmd+2 $lmt[4,4068,20,4084] $lb128; l1bmd+1 $lbi $ln[4094,30,0,0]/1100 l1bmd+3 $lmt[6,4070,22,4086] $lb0; l1bmd+2 $lbi $ln[4092,28,0,0]/1100 l1bmd+4 $lmt[8,4072,24,4088] $lb512; l1bmd+3 $lbi $ln[4090,26,0,0]/1100 l1bmd+5 $lmt[10,4074,26,4090] $lb384; l1bmd+4 $lbi $ln[4088,24,0,0]/1100 l1bmd+6 $lmt[12,4076,28,4092] $lb896; l1bmd+5 $lbi $ln[4086,22,0,0]/1100 l1bmd+7 $lmt[14,4078,30,4094] $lb768; l1bmd+6 $lbi $ln[4084,20,0,0]/1100 l1bmd+8 $lmt[16,4080,0,0] $lbi; l1bmd+7 $lbi $ln[4082,18,0,0]/1100 l1bmd+9 $lmt[18,4082,0,0] $lbi; l1bmd+8 $lbi $ln[4080,16,0,0]/1100 l1bmd+9/1100 $lbi $ln[4078,14,4078,4078]/1100 l1bmd+8 $lb128 $ln[4074,10,4076,12] l1bmd+8 $lb512 $ln[4070,6,4072,8] l1bmd+8 $lb896 $ln[4066,2,4068,4]
Inversion Small
全体ベスト: 10行 自己ベスト: 10行
問題概要: 長さ16のulongの配列の転倒数を計算する。入力はPE, MAB間で放送されている。
解法概要: 愚直にO(N2)回の比較を行います。 オフセットを変えて並列に比較してから縮約することで高速化できます。 PE間とサイクル間の縮約に半精度行列積を利用することで、かなり縮みました。 マスクを利用して浮動小数点数→整数の変換をすることでさらに縮んで10行になりました。
Inversion
全体ベスト: 31行 自己ベスト: 31行👑(単独ベスト)
問題概要
長さ64のuintの配列の転倒数を計算する。 1長語内に2ケース分の入力がパックされている。つまり、MSB側単語とLSB側単語で別の配列の値となっており、それぞれ独立して転倒数を計算する。 入力はL1B,L2B間で放送されている*17。 逆に、MAB,PE間では分配が行われているため、それぞれ独立した問題を解くことになる。
解法
L1B,L2B間で並列に計算してから縮約することで高速化します。
素直にやると4096回比較することになるが、うまくやることで比較回数を減らすことができます。
まず、$l1bid, $l2bidをそれぞれj,kのインデックスの下位ビットになるようにします。
すると、上位ビットはコンパイル時に与えるオフセットになるので、必ず負のアドレスが続く部分は計算しなくてよくなります。
PEあたり64回の比較を36回の比較に削減できるので、比較演算にかかるステップ数を16ステップから9ステップに削減できます。
比較演算はALUで行う必要があるため、その個数の集計はMAUでやると並列実行できます。 これで35行ぐらいになりました。
ここから整数への変換をマスクに置き換えたり、比較対象値の読み込み時間を隠蔽したり、L2BM→L1BM転送からL1BM→PE転送の間のステップ数を削減したりで31行になりました。
ipackbit $l2bid $ls128 $mb imm i"0x49800010" $ln64v $ls64v ipackbit $l1bid $ls128 $t; fvmul $aluf $aluf $lr2v4 spassa $lm64v16 $ls168v; hvpassa -$mauf $omr3 isub $aluf $lmt[4080,4080,4080,4080] $omr1; fvadd $lr2v4 $ls64v $lr0v4 $ls0v4 isub $ls168 $lmt0v16 $omr2; fvadd $mauf -$ln64 $lr0v4/$imr1 $ls0v4/$imr1; l1bmd $lmt0v16 $lbi isub $ls170 $lmt0v16 $omr1; fvadd $lr2v4 -$ln64 $lr2v4/$imr2; l1bmd $lbi $nowrite; l1bmd $lmt0v16 $lbi isub $ls172 $lbf $omr2; fvadd $lr0v4 -$ln64 $lr0v4/$imr1 $ls0v4/$imr1; l1bmd $lbi $nowrite; l1bmd $lm0v16 $lbi isub $ls174 $lbf $omr1; fvadd $lr2v4 -$ln64 $lr2v4/$imr2; l1bmd $lbi $ls160v isub $ls[170,172,172,174] $lmt[64,64,80,64] $omr2; fvadd $lr0v4 -$ln64 $lr0v4/$imr1 $ls0v4/$imr1 isub $ls[174,174,160,162] $lmt[80,96,4080,4080] $omr1; fvadd $lr2v4 -$ln64 $lr2v4/$imr2 isub $ls[162,164,164,164] $lmt[0,4080,0,16] $omr2; fvadd $lr0v4 -$ln64 $lr0v4/$imr1 $ls0v4/$imr1 isub $ls[166,166,166,166] $lmt[4080,0,16,32] $omr1; fvadd $lr2v4 -$ln64 $lr2v4/$imr2 fvadd $lr0v4 -$ln64 $lr0v4/$imr1 $ls0v4/$imr1 fvadd $lr2v4 $ls[256,256,256,0] $lr16v; fvadd $mauf $lr[256,2,12,2] $lr24v; fvadd $mauf $lr[256,4,22,256] $lr32v; fvadd $mauf $lr[256,8,256,256] $nowrite fvadd/$imr3 $mauf $lr[256,36,256,256] $lr48v l1bmd $mauf $lb0 nop nop l2bmriiadd $lb64 $lc0 nop mvriiadd/n64 $lc0 $p0@0 mvb/n64 $p0@0 $lc0 nop nop l2bmb $lc0 $lb192 nop l1bmd $lb0 $ln0/0001
感想
無職の有り余る時間をつぎ込んでなんとか優勝することができました。 テクニックの発見にはかなり労力がかかりがちなので、その点で時間をつぎ込めたのは大きかった気がします。 コンテストが今後も開催されれば、すでに細かいテクニックがみんなに知られた状態でスタートするので、今回よりは少ない時間で同じラインまでたどり着けるであろうことを考えると、時間の優位性は薄くなるかもしれません。
全体的には非常に楽しかった(とはいえなかなか縮まない時間はつらい時間でもあったが…)のですが、ひとつ心残りとしてはFizzBuzzを解かなかったことでしょうか… あとでPFN社内記録を超えておきます。
*1:外部メモリのアクセス等にはある程度の不確定性があり、実機では外部メモリアクセス後に明示的な同期が必要になる
*2:MAB内の通信はかなり貧弱だが…
*3:ぎちぎちに命令を詰めようとするとサイクル単位での最適化が必要なためこの限りではない
*4:一部倍速・半速の演算もある
*6:ただし、一般的なFP16・BF16とは異なるフォーマット
*7:MN-Coreはビッグエンディアンなのでアドレス的には後半1長語
*8:たくさんの命令が必要になってしまう
*9:演算結果を半精度に縮減したりもできる
*10:指数部に3を足す用
*11:全問解説するのはさすがにしんどい
*12:今回はminだけ使いました
*14:FizzBuzzとこの問題だけPFN社内ベストの方が短いらしい
*15:modを取ること自体は0b1111でマスクを取るなどでよく、重い計算ではない
*16:とSDMには書いてあるが、折り返しでmabdiffの値が異なるとそもそもエラーになるため、先にずらしているか後でずらしているか外からは観測できないと思われる
*17:ほかの多くの問題でもL1B, L2B間で放送されているが、それが活用できるほど行数に余裕がない
Brainf*ckを直接実行できるCPUを作った (その4) BTB(Branch Target Buffer)の実装【いろいろなコンピューター Advent Calendar 2023 13日目】
この記事はいろいろなコンピューター Advent Calendar 2023の13日目の記事です。年跨いだけど気にしない。 adventar.org
この記事は12日目の記事の続きです。ぜひ先にそちらをご覧ください。 primenumber.hatenadiary.jp
前回の記事では、パイプライン化に成功し、自分のFPGAでは170MHz程度が最大動作周波数でした。 そのあと、命令メモリの回路構成を少し見直すことで、250MHzくらいまで出せるようになりました。
今回は、Brainf*ck CPUにBTB(Branch Target Buffer, 分岐先キャッシュ)を実装していきます。
Brainf*ck CPUにおける分岐の扱い
通常の命令セットのCPUであれば、命令自体に絶対・相対アドレスが入っていたり、レジスタの値を元にジャンプするので、少なくとも命令を実行する時点ではどこにジャンプすればよいかが判明します*1。
しかし、Brainf*ckではそうはいきません。
[ ] によるジャンプが発生したとき、ジャンプ先は対応する ] [ になります。
対応する ] [ の位置は命令列を見ないとわからないため、その位置を探索する必要があります。
前回の記事の時点では、分岐が発生するたびに、命令列を走査して対応する] [を探していました。
これには、ジャンプする距離に比例するサイクル数が必要になってしまいます。
前回パイプライン化まで実装したことで、] [の探索が実行時間の半分以上を占める*2ようになってしまいました。
結合テスト・ベンチマークで用いているHanoi4.bfの実行では、命令実行に14803サイクル、ジャンプ先探索に21352サイクルかかっていました。
分岐先のキャッシュ
Brainf*ck CPUでは、分岐先を求めるのが高コストな一方で、あるアドレスから分岐するとき、その分岐先アドレスはプログラム実行中常に一定です。 そこで、分岐先を探索後、探索結果を保存することで、次回同じ場所で分岐したときに、探索の代わりに保存した結果を使うことで、探索を省略できるようにできます。
分岐先アドレスを保存するこの機構をBranch Target Buffer(BTB)、あるいはBranch Target Address Cache(BTAC)と呼びます。
通常の命令セットのCPUでは、分岐元のアドレスが同じでも分岐先が変わることがあり得ますが、Brainf*ck CPUでは変化しないため、比較的簡単に実装できます。
BTBの実装
できたものがこちらになります
BTBの実装はBTB.scalaにあります。
BTBは小さなメモリに探索結果を保存することで実現します。
分岐元アドレスの下位ビットをキャッシュメモリのアドレスとして用います。 もし下位ビットが同じで上位ビットが異なるアドレスについてキャッシュに書き込むと、以前の内容は消えてしまいますが、そのときは再度探索を行うことにします。
下位ビットを元に直接保存場所が決定する方式のキャッシュを、ダイレクトマップ方式といいます。 実装は簡単ですが、セットアソシアティブ方式等に比べるとキャッシュミスが増加してしまいます。
実験の結果、ダイレクトマップ方式でも十分な性能向上が得られたため、ダイレクトマップ方式のままでいくことにしました。
キャッシュメモリにはvalidフラグ、分岐元アドレスの上位ビット(キャッシュメモリのアドレスとして使わなかった部分)、分岐先アドレスを保存します。
validフラグは、キャッシュメモリから読んできた内容が有効かを判定するのに必要です。 キャッシュメモリを最初validが0のデータで埋めておき、キャッシュに書き込むときにはvalidが1のデータを書き込むことで、内容の有効性を判定できます。
分岐先アドレスの上位ビットは、キャッシュメモリから読んできた内容が欲しいアドレスの内容かどうかを判定するのに必要です。
命令フェッチのレイテンシーの隠蔽
命令フェッチには現状2サイクル必要です。分岐命令を処理した次のサイクルでは、分岐後の命令がまだフェッチできていないため、このままでは1サイクルストールする必要があります。
そこで、BTBに分岐先アドレスだけでなく、ジャンプ後の次の命令も一緒に保存することにします。
BTBヒット時には、命令メモリから命令がやってくるのを待たずに、BTBに保存した命令を使うことで、命令フェッチのレイテンシーを隠蔽し、パイプラインを止めることなく分岐が可能になりました。
ベンチマーク
ベンチマークに用いているHanoi4.bfでの結果をまとめてみました。Hanoi4.bfは455bytesであるため、512エントリあれば衝突は絶対に発生しなくなります。
| BTBエントリ数 | 命令実行サイクル数 | ジャンプ先探索サイクル数 |
|---|---|---|
| なし | 14803 | 21352 |
| 2 | 14803 | 12224 |
| 4 | 14803 | 12172 |
| 8 | 14803 | 11491 |
| 16 | 14803 | 7776 |
| 32 | 14803 | 1957 |
| 64 | 14803 | 1643 |
| 128 | 14803 | 1643 |
| 256 | 14803 | 1643 |
| 512 | 14803 | 1643 |
エントリ数がそれなりにあれば、ジャンプ先探索にかかるサイクル数が、BTBがない状態と比べて1/10未満になっています! 全体でも半分以下のサイクル数になっており、すばらしい性能向上です。
また、64エントリ以上はサイクル数がかわっていないことから、衝突が起きていないことが分かります。
ちなみに、BTBの追加でUltra96-V2 | Avnet Boardsでの最大動作周波数は220MHz程度と、若干下がってしまいました。 それでもサイクル数の削減の効果の方が圧倒的に大きいため、実時間ベースでも約半減になっています。 動作周波数を上げるボトルネックになっているクリティカルパスは、命令アドレス生成・命令フェッチまわりのようです。 これはちょっとすぐには解決が難しそうです。
今後の展望
ここまでの改良で、(BTBエントリが衝突しない限り)1サイクルあたり1命令実行に限りなく近づけることができました。 個人的にここまでは実装したいな、と思っていたのでよかったです。
ここからさらに性能を向上させるには、2通りのアプローチがあります。
- 1サイクルの間に1命令より多くの命令を処理する
- op fusionとfusion済み命令キャッシュの実装
- スーパースカラ実行の実装
- 動作周波数を上げる
- パイプラインステージの分割
構造の複雑化で、最大動作周波数が下がってきているので、パイプラインステージの分割はぜひともやりたいところです。 命令デコードと実行をステージ分割することで、op fusionにつなげられるとよりうれしいですが、果たして…
スーパースカラ実行は、Brainf*ckの命令レベルの並列性のなさが原因で、圧倒的に難易度が上がりそうで、実装できるかちょっと自信がないです。
Brainf*ckを直接実行できるCPUを作った (その3) パイプライン化とデータキャッシュ【いろいろなコンピューター Advent Calendar 2023 12日目】
この記事はいろいろなコンピューター Advent Calendar 2023の12日目の記事です(大遅刻)。
この記事は10日目の記事の続きです。ぜひ先にそちらをご覧ください。
10日目の記事で実装したいとしていた
- 命令書き込みモードを作る
[によるジャンプと]によるジャンプで状態を分けているが、進む向きが違うだけなので共通化する
はすぐにできたので、この記事ではついにCPUのパイプライン化を実現します。
Brainf*ck CPUにおけるデータハザード
Brainf*ck CPUをパイプライン化するうえでもっとも困難なことは、データハザードです。

1命令でメモリからのデータの読み込み→計算→メモリへのデータの書き込みを行うため、メモリアクセスを含めてパイプライン化する必要があります。 連続で+や-を行った場合、当然読み書きするアドレスは同じです。 そこをなにも考えずにパイプライン化すると、直前の命令で得られた結果をメモリに書き込む前に、次の命令が必要とするデータの読み込みが発生*1してしまい、内容が壊れてしまいます。 これをデータハザードといいます。
レジスタマシン(今日一般的なCPUのアーキテクチャ)では、EXステージの結果をレジスタに書き込むと同時に、(必要なら)次の命令の入力に直接渡す、フォワーディングと呼ばれる方法が使われています。
Brainf*ck CPUでも、直前に使ったアドレスと同じアドレスにアクセスするのなら、そのデータをフォワーディングすることでデータハザードを回避できます。
しかし、アクセスするアドレスが変わるとデータを読み直す必要があり、このときはメモリからデータがやってくるまで待つ(ストールする)ことになります。 これでは頻繁にストールしてしまい、あまり性能が出なくなってしまいます。
データキャッシュの実装
そこで、メモリの内容を一部だけCPU内に保持することにします。 つまりデータキャッシュを実装すればよいことになります。
一般的なCPUに対するデータキャッシュでは、アクセス先を予測することは困難であるため、効率の良いキャッシュの実装はかなり難易度が高いです。 幸いにも、Brainf*ckではデータアクセス先は1命令あたり高々1byteずつしか動かないため、データポインタの周囲数bytesを保持しておくだけでよいです。

今回は、データメモリに1サイクル後にアクセスできる想定で、データポインタの指す先とその前後1byteずつ、合計3bytesを保持するキャッシュを実装しました。
挙動としては、データポインタをインクリメントするときは、(データポインタ+2)番地のメモリを読みに行き、デクリメントするときは(データポインタ-2)番地のメモリを読みに行きます。
こうすることで、データポインタを移動させていったときに、データが欲しいときには常にキャッシュに載っているようにすることができます。
また、毎サイクルデータポインタの指す場所にキャッシュの内容を書き込みます。
データキャッシュの実装はDCache.scalaにあります。
パイプライン化
これで無事データハザードが解決できると、あとは比較的スムーズにパイプライン化することができました(デコード/実行が1ステージになっているなど、3ステージしかないのも楽な理由)。
分岐予測等は実装していないので、分岐(ジャンプ)が発生したときには、素直に命令フェッチからやり直します。
できたものがこちらになります。
今後の展望
直近で実装したいのは次の二つの機能です。
分岐先キャッシュの実装
パイプライン化の結果、実行時間の多くを[ ]命令の対応する] [を探すことに費やすようになりました。
ジャンプ先アドレス(とジャンプ先からの数命令)をキャッシュすることで、即座にジャンプできるようになると、大幅な高速化が期待できます。
パイプラインステージの追加
FPGAのBlock RAMは読みだしたデータを一旦レジスタに受けることで、アクセスまでのサイクル数増加と引き換えに、最大動作周波数の向上を狙うことができます。 現状ではレジスタで受けていないため、動作周波数をあまり上げることができません。
今の設計では、私の持っている Ultra96-V2 | Avnet Boards では170MHz程度が上限のようでした。
メモリからの読み込みをレジスタで受け、追加のパイプラインステージを追加することで、最大動作周波数を向上させ、トータルの性能向上を狙っていきたいです。 場合によっては、命令デコードと命令実行をステージ分割することで、さらなる最大動作周波数の向上が可能かもしれません。
(追記) その4はこちら
*1:図における命令Bのloadが命令Aのwritebackに先行してしまう